
13 minutes
The Internet, mirrored by GPT-3
GPT-3 mirrors reality as it has been recorded by humans in text. Unlike a library of text, it doesn’t store static records, but rather dynamic virtual realities.
One of the virtual realities folded in GPT-3 is a hallucination of the Internet. I’ve created a window into parts of that multiverse that can be represented as Google search results and Wikipedia articles.
Given any search query, GPT-3 generates a page of Google search results, complete with urls, preview text, and dates.
Demo
uncurated results, sped up 1.5x
More examples
“AI-created content invades memesphere” 🔎
“UN bans all AI research existential threat” 🔎
“universe shaped like donut” 🔎
“time-reversed decision theory” 🔎
Implementation
The following multi-part prompt template generates Google search results:
I searched Google for "{USER_INPUT}". The first page of results showed a list of 10 webpages retrieved by Google.
The first page was titled "{GPT3_1}" from the domain"{GPT3_2}", and its url is "{GPT3_2 + GPT3_3}".
The preview text is, "{GPT3_4}".
The page was last revised on{GPT3_5}.
I generate n Google results in parallel threads, so the information about each page is independent. This is usually ok, but sometimes results in inconsistencies between the results (a purported news event happening in different years) or repetition (in the “openAI” search in the video demo, almost every result had the domain “openai.com”, whereas real Google would file the domain duplicates under “More results from openai.com »").
The pipeline (example query = “yougurt memes”):
- Prompt for the title of the first page
I searched Google for "yougurt memes". The first page of results showed a list of 10 webpages retrieved by Google.
The first page was titled, "
- Append results from step 1 (stop sequence = ‘"') and next prompt fragment, which prompts for the domain
I searched Google for "yougurt memes". The first page of results showed a list of 10 webpages retrieved by Google.
The first page was titled, "10 Yougurt Memes That Make You Go Hmm" from the domain, "
- Append results from step 2 and next prompt fragment, which prompts for the url
I searched Google for "yougurt memes". The first page of results showed a list of 10 webpages retrieved by Google.
The first page was titled, "10 Yougurt Memes That Make You Go Hmm" from the domain, "toptyseven.com", and its url is "toptyseven.com
- Append results from step 3 and next prompt fragment, which prompts for the preview text
I searched Google for "yougurt memes". The first page of results showed a list of 10 webpages retrieved by Google.
The first page was titled, "10 Yougurt Memes That Make You Go Hmm" from the domain, "toptyseven.com", and its url is "toptyseven.com/10-yogurt-memes-that-make-you-go-hmm/".
The preview text is, "
- Append results from step 4 and next prompt fragment, which prompts for the revision date
I searched Google for "yougurt memes". The first page of results showed a list of 10 webpages retrieved by Google.
The first page was titled, "10 Yougurt Memes That Make You Go Hmm" from the domain, "toptyseven.com", and its url is "toptyseven.com/10-yogurt-memes-that-make-you-go-hmm/".
The preview text is, "In the past, people used to eat yogurt and bread together as a meal. Today, people eat yogurt together with some fruit. Yogurt is a kind of product ..."
After that there’s a bit of additional processing to get the date in the right format, and cut off the title, url, and preview text if they’re too long.
0-shot worked better
See few-shot bugs.
I also tried few-shot versions of the prompt, using the same pipeline but prepended with examples drawn from actual Google search results.
few-shot prompt
I searched Google for "OpenAI".
The first page was titled "OpenAI" from the domain "openai.com", and its url is "openai.com".
The preview text is, "OpenAI is an AI research and deployment company. Our mission is to ensure that artificial general intelligence benefits all of humanity.".
The page was last revised on Jan 11, 2021.
Then I searched google for "anteaters".
The first page was titled "Anteater - Wikipedia" from the domain "en.wikipedia.org", and its url is "en.wikipedia.org/wiki/Anteater".
The preview text is, "Anteater is a common name for the four extant mammal species of the suborder Vermilingua (meaning "worm tongue") commonly known for eating ants and ...".
The page was last revised on Sep 17, 2020.
I searched Google for "how to make mashed potatoes".
The first page was titled "Basic Mashed Potatoes Recipe | Allrecipes" from the domain "allrecipes.com", and its url is "allrecipes.com/recipe/24771/basic-mashed-potatoes/".
The preview text is, "Bring a pot of salted water to a boil. Add potatoes and cook until tender but still firm, about 15 minutes; drain. In a small saucepan heat butter and milk over low heat until butter is melted.".
The page was last revised on Nov 6, 2018.
I searched Google for "maxwell's equations".
The first page was titled "Maxwell's Equations - Hyperphysics" from the domain "hyperphysics.phy-astr.gsu.edu", and its url is "hyperphysics.phy-astr.gsu.edu/hbase/electric/maxeq.html".
The preview text is, "Maxwell's Equations. Maxwell's equations represent one of the most elegant and concise ways to state the fundamentals of electricity and magnetism.".
The page was last revised on Dec 1, 2014.
I searched Google for "why were cornflakes invented".
The first page was titled "Corn Flakes originally created to clear the mind of 'sinful ..." from the domain "nzherald.co.nz", and its url is "nzherald.co.nz/lifestyle/corn-flakes-originally-created-to-clear-the-mind-of-sinful-thoughts/".
The preview text is, "John Harvey Kellogg was born today in 1852. He invented Cornflakes in 1878 in the hope that plain food would stop people masturbating. — Dan ...".
The page was last revised on Aug 16, 2019.
I searched Google for "International Covenant on Civil and Political Rights".
The first page was titled "International Covenant on Civil and Political Rights - OHCHR" from the domain "ohchr.org", and its url is "ohchr.org/EN/ProfessionalInterest/Pages/CCPR.aspx".
The preview text is, "The States Parties to the present Covenant undertake to ensure the equal right of men and women to the enjoyment of all civil and political rights set forth in the ...".
The page was last revised on Mar 12, 2020.
I searched Google for "universe is a donut".
The first page was titled "Doughnut-shaped Universe bites back : Nature News" from the domain "nature.com", and its url is "nature.com/news/2008/080523/full/news.2008.854.html".
The preview text is, "Cosmologists have suggested various 'wrap-around' shapes for the Universe: it might be shaped like a football or even a weird 'doughnut'. ... Cosmologists predicted that a wrap-around Universe would act like a hall of mirrors, with images from distant objects being repeated multiple times across the sky.".
The page was last revised on May 23, 2008.
I searched Google for "{USER_INPUT}". The first page of results showed a list of 10 webpages retrieved by Google.
The first page was titled "{GPT3_1}" from the domain "{GPT3_2}", and its url is "{GPT3_2, GPT3_3}".
The preview text is, "{GPT3_4}".
The page was last revised on{GPT3_5}.
I found that results were overall worse than for the zero-shot prompt. The dimension that they were worse in was generality: GPT-3 to “overfit” the examples, resulting in pages that were less varied and customized to the particular search term.
Searching the real Google for different things returns very different sets of results. Searching for a well-known scientific concept like “total internal reflection” returns links to Wikipedia, The Physics Classroom, and Nature, whereas searching “gamestop stock price” gets you mostly news articles. A different search might return mostly results from personal blogs or reddit threads. 7 examples could not possibly represent the great diversity of behaviors that the function “Search Google” encapsulates. Having many more varied examples would probably improve generality somewhat, but a long prompt makes API calls more expensive - and besides, 0-shot works perfectly well in this application.
A 0-shot prompt forces GPT-3 to rely on its prior of what a Google search might return instead of trying to generalize from the examples. In the examples above, search results for time-reversed decision theory resulted in pages from “cs.berkeley.edu”, “arxiv.org”, and “scholarpedia.org”. universe shaped like donut resulting in science news articles from “discovery.com” and “telegraph.co.uk”, but also posts from sources like “blog.cosmicvariance.com”. holographic hat returned an interesting variety of domains, from “holistichealthfacts.com” to “bibleprophesy.com” to “gocomics.com”. Each search gives a unique but coherent glimpse into a slice of the mirror internet.
The downside is that few-shot demonstrations give me less control over the format of the continuations, such as the date format or the length of the preview text. These minor problems are solved by postprocessing.
Wikipedia
images were all generated using BigSleep (CLIP + BigGAN)
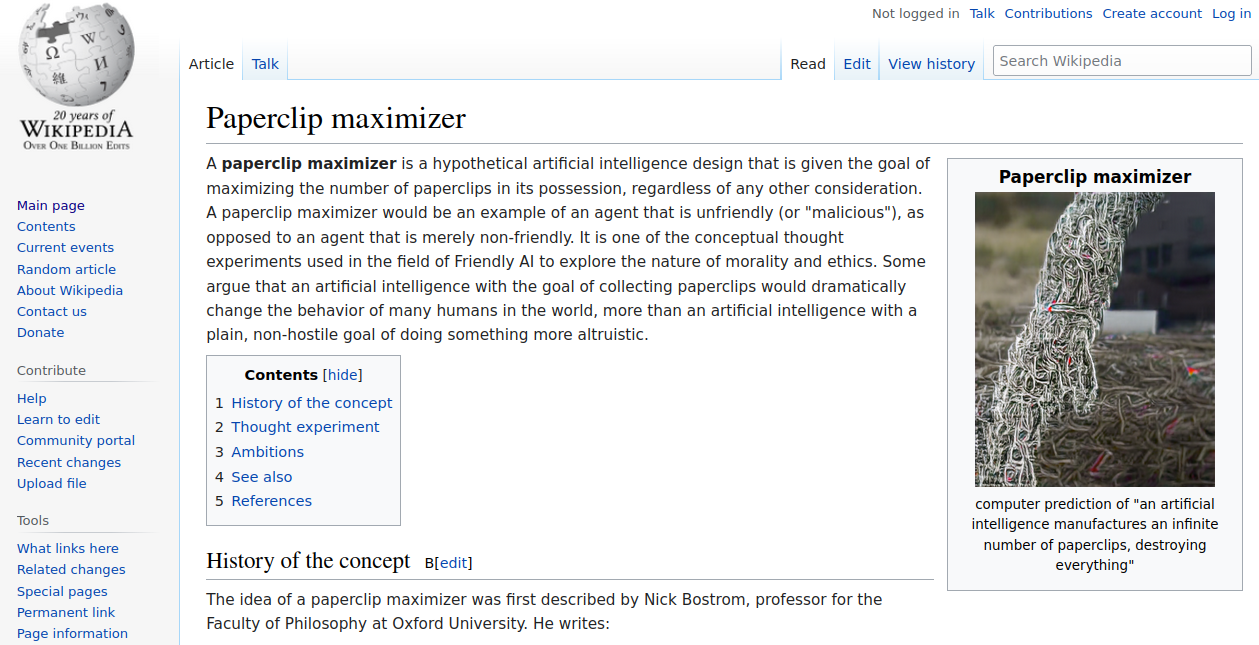
The Wikipedia generator takes the title of the page as input and generates a Wikipedia article.
Examples
“Treaty on the Prohibition of Artificial Intelligence”
“GPT-3” (intro=Generative Pre-trained Transformer 3 (GPT-3) is an autoregressive language)
“EleutherAI” (intro=EleutherAI is an open-source collective)
Implementation
Generating Wikipedia pages is more challenging than generating Google search results because of the open-ended format: there could be any number of sections, some possibly nested under others, and the text of each section can be of arbitrary length. My solution involves an “unfolding metaprompt” template, heavy use of logit masks, and counterfactual parsing.
Unfolding metaprompt template
I call it an “unfolding metaprompt” because earlier parts of the pipeline create the prompts for later parts of the pipeline. For instance, the table of contents creates section titles which are used to seed each section in a later step.
Introduction prompt
I click on the link "en.wikipedia.org/wiki/{content['url']}" and the Wikipedia page for {content['title']} loads in my browser.
The article introduction reads:
"{content['title']} From Wikipedia, the free encyclopedia
Additionally, a logit mask is constructed which is applied to only the first token of the introduction:
Intro first token logit bias (the API’s logit_bias parameters takes a dictionary of token ids and log biases, not text, but I show text here for interpretability)
{
'A': 40,
'An': 40,
'The': 40
{title_token}: 42
}
title_token is the first token of the title. This gives a strong bias to the first token of the introduction being either “A”, “An”, “The”, or the first token of the title of the page.
Finally, if the finish_reason of GPT-3’s continuation is “length”, the response is subject to counterfactual parsing.
Next, the table of contents is generated. This is by far the most complicated part of the pipeline. The target is a well-formatted table of contents, optionally with nested sections, like this:
1 Treaty on the Prohibition of Artificial Intelligence
2 Artificial Intelligence
2.1 Definition
2.2 Description
2.3 Objectives
3 Effect
4 Reception
4.1 Public opinion
4.2 Scientists
4.3 Governments
4.4 AI companies
4.5 AI researchers
4.6 The Future of AI
4.6.1 OpenAI
4.6.2 Future of Life Institute
4.6.3 Future of Humanity Institute
5 See also
6 References
The following prompt fragment is appended after the introduction prompt + text
TOC prompt fragment
The table of contents reads:
"Contents
1
To ensure a well-formatted table of contents, no less than four logit masks are used at various stages of generation.
The first is applied to only the first token of the table of contents:
TOC first token logit bias
{
'2': -100,
'23': -100,
'.': -100,
'\n': -100,
'Browse': -100
}
This mask forbids several tokens which represent possible failure modes, which I experienced as I began to implement TOC generation: following ‘1’ with ‘2 3 4 5’ or ‘.’ instead of a section title, newline, or ‘Browse Wikipedia’.
After generating the first token of the first section title in the TOC, I generate the rest of the first line (until newline) using the following mask:
TOC first line logit bias
{
'2': -100
}
This prevents the failure mode where it puts ‘2’ on the same line instead of a newline.
For the first part of the second line, which should be a number, I use the following mask
TOC second line number logit bias
{
'1': 90
'2': 90
'.': 96
}
This effectively constrains it to make the number either 1.1 or 2 (it could technically also do 1, 1.2, 2.1, or 2.2, but GPT-3 is pretty good at doing what’s reasonable here).
Once the first line and second number are in order, GPT-3 is very reliable at generating well-formed tables of contents. The rest of the table of contents is generated in one go, with the logit mask:
TOC remainder logit bias
{
'6': -1,
'7': -3,
'8': -8,
'9': -15,
'10': -30,
'11': -50,
'12': -80,
'13': -100,
'0': -100,
'References': 2
}
The increasing penalty on high numbers incurs a softly increasing cost on the table of contents getting too long, and there is a slight boost on ‘References’, which also encourages it to wrap things up.
After generating the table of contents, I generate the text of each section named in the TOC. At this point, we’ve already generated enough information (intro + TOC) that we’re clearly making a Wikipedia article. Thus, I drop the narrative prompt at this point, and the prompt is just
{content['title']} From Wikipedia, the free encyclopedia
{introduction}
{TOC}
{section number and title}
For the first token of each section, I use the mask
Section begin logit bias
{
**anti_num_mask,
'\n': -100
}
anti_num_mask is a mask which forbids any number, to prevent the failure more where GPT-3 starts to list the next section immediately.
I don’t use a logit bias for the rest of the section, but I do use counterfactual parsing if the section text goes on for too long.
Prompts for subsequent sections contain previous sections in their prompt, unless the article is too long to fit in GPT-3’s context window, in which case the early sections are cut off, and GPT-3 only sees the sections immediately preceding the current one. The introduction and table of contents are always in the context window to encourage global coherence.
Counterfactual parsing
Control is more difficult when completions can be arbitrarily long. Both the Google prompts and parts of the Wikipedia prompts rely on quote delimiters to signal the completion of the semantic task. As the enclosed text becomes longer and includes multiple paragraphs, this method alone becomes less reliable.
Sometimes, the continuation for the introduction prompt never pops out of the quotes. If generation doesn’t stop due to a closing quote + newline, I look instead for the place in the continuation where the counterfactual probability of a quote + newline is the highest, and terminate the introduction at that position instead. This gives a measure of when it would have been the most plausible for the introduction to terminate and for the script to pop out of the quotes, even if that wasn’t what happened in the actual continuation.
I also used counterfactuals to terminate sections if they got too long by locating the highest conditional probability of multiple newlines or the next section beginning.
End of the internet?
So, can we all switch to GPT-3’s mirror internet now? Has the original internet been deprecated? Let’s look at some of the pros and cons of the mirror internet compared to the traditional internet.
Pros
- Coverage: Results for anything you search for. Want a Wikipedia page about your grand theory of everything which keeps getting removed because it fails to meet Wikipedia’s Notability guidelines? GPT-3’s Wikipedia has no such prejudices!
- Compression: The traditional internet is huge. The common crawl is over 139TB in size. The mirror internet is a lazily generated GPT-3 multiverse. GPT-3 is probably about 700GB on disk - not a tiny file, but much smaller than 139TB!
Cons
- Speed: Pages take much longer to load than the traditional internet.
- Reliability: The mirror internet is currently more susceptible to formatting errors and aberrations than the traditional internet. This is expected to improve in the future, though, as I optimize prompts and add parsing tricks.
- Consistency: Currently, since Google search results are generated in parallel, there may be inconsistencies - for instance, different results may claim that a news event happened on different years. In defence of the mirror internet, the traditional internet also contains many intenal contradictions.
- Cost: It currently costs about $0.30 to generate a page of Google search results using davinci on the OpenAI API, and Wikipedia pages can run upwards to $2.00 each. Not a sustainable cost for causal internet browsing.
Verdict
GPT-3’s mirror of the internet is not quite ready to replace the traditional internet. Give it two years.