
27 minutes
Language models are multiverse generators
Actualities seem to float in a wider sea of possibilities from out of which they were chosen; and somewhere, indeterminism says, such possibilities exist, and form part of the truth.
– William James
 Tree from seed
Tree from seed In the beginning, GPT-3 created the root node of the (view full)
{kind=link}
Language models are time evolution operators
Autoregressive language models like GPT-3 input a sequence of tokens and output a vector associating a value with every possible token representing its likelihood to come next. Humans can’t read probability distributions (statisticians may try), so an additional step is required: a single token is sampled from the distribution and then appended to the prompt, which becomes the next input to the next timestep. If the language model’s predictions square with our sensibilities, repeating this procedure is likely to yield a passage of coherent text.
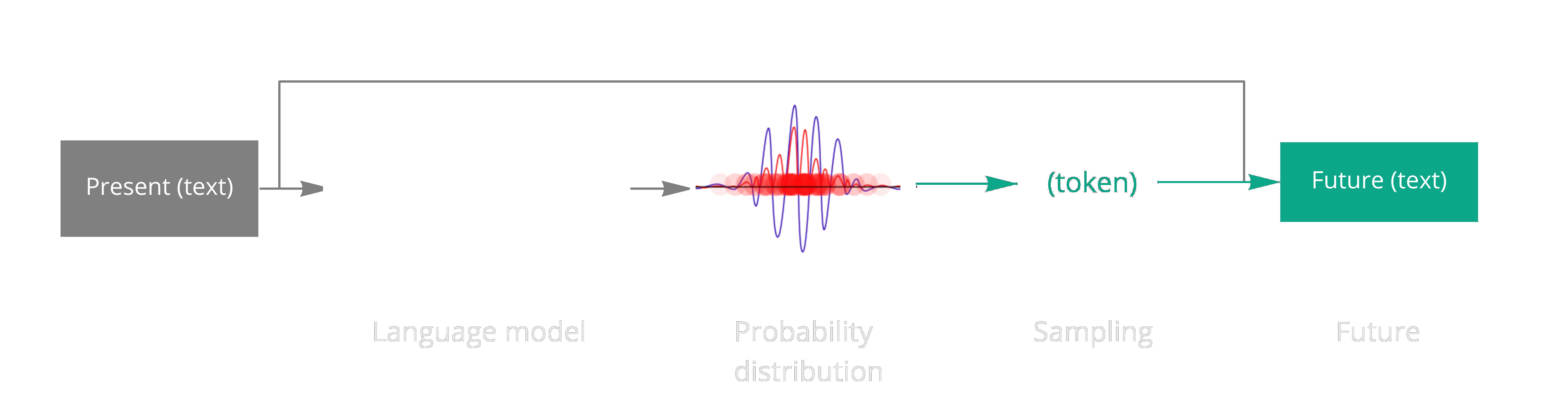 The usual way of running a language model generatively. The future text becomes the present text of the next timestep, and repeat.
The usual way of running a language model generatively. The future text becomes the present text of the next timestep, and repeat.
The language model plays an analogous role to that of the time evolution operator in physical reality. The time evolution operator - call it Ĥ - encodes all relevant physics. It takes the state of a system at time t as input and gives the state of the system at time t+dt as output. Ĥ is deterministic: for any input, it will always return the same output. In quantum reality, however, the format of the output of Ĥ is not a single state of affairs but a probability distribution over all possible states of affairs. Rather than telling us the position of a photon, quantum mechanics gives us the probability we can expect to measure a photon at any position.
As far as we know, the most precisely we can predict any system is to model it with quantum mechanics. If this is true, then the future is fundamentally indeterminate. The problem is not merely epistemic. The future truly has not yet been written, except in probabilities. However, when we do venture to measure it, the ambiguous future seems to us to become a concrete, singular present, and subsequent evolution seems to depend only on the outcome that was measured. The other possibilities no longer affect our reality, rather like when a token is sampled from the probabilistic output of a language model and appended to the prompt in the next timestep.
[Technicality]
The most blatant incongruity in the analogy of quantum Hamiltonian :: autoregressive LM is that the Hamiltonian sends wavefunction to wavefunction whereas language models send a determinate single history to an indeterminate future distribution. However, observers do seem to primarily experience reality as an ongoing sampling of indeterminate futures into determinate pasts. The decoherent parts of the wavefunction have no effect, even though they are technically still included in the input to the Hamiltonian at each timestep. The exception is interference phenomena, where alternative pasts have not decohered from the observer and can mutually affect the present. Also, language models don't have to take a single-history token sequence as input (though APIs generally do) - you could feed a superposition of inputs or anything you want to a language model and see what happens. I'd like to see what happens.This phenomenon of counterfactual possibilities ceasing to affect our reality after measurement is known as “wave function collapse”, referring to the apparent reduction of the continuous probability distribution (wave function) into a discrete value. According to the Copenhagen interpretation of quantum mechanics, there is no reality except that which is observed - after measurement, the alternative possibilities cease to exist (and they never existed in the first place except as epistemic uncertainty).
“This is you, if you decide to turn left.”
“If– if I go right, then does this one disappear?”
“No. Not at all. All possible you’s remain in the weave of the future. Even the ones that have diverged into other, different pathways still exist. All possible you’s are real, in some sense of the word. The left-you and right-you’s are still here,” you say, “but they just lead down different paths.”
Your hands unfold, stretching the fabric of reality back into place.
– GPT-3
The Everettian or many-worlds interpretation of quantum mechanics views the situation differently. It claims that we, as observers, live in indeterminacy like the world around us. When we make a measurement, rather than collapsing the probabilistic world around us into a single present, we join it in ambiguity. ``We” (in a greater sense than we normally use the word) experience all of the possible futures, each in a separate branch of a great multiverse. Other branches quickly become decoherent and evolve separately, no longer observable or able to influence our subjective slice of the multiverse.
This is the fundamental Reality Thread. It’s a thin strand of possibility, following a line of probability for the purposes of modelling. Now, the interesting thing about reality, is that it’s not fixed. Not at all. You can change it just by looking at it.
– GPT-3
[Note on Copenhagen vs Everett]
The Copenhagen and Everettian interpretations don't technically disagree on any low-level predictions. All the ways in which we can indirectly probe the multiverse are permitted by the Copenhagen interpretation, except that it does not assign reality to things that happen in different branches, even if they have measurable effects on our branch. However, physical evidence can make metaphysical perspectives more or less attractive. If we someday figured out how to make an entire person split into two, perform complex activities (for instance, solve separate pieces of a cryptographic problem in the different branches), and then interfere with themselves like a photon does, it would be a lot more awkward to uphold the perspective that none of that really happened!If only we were outside the system, we could watch the many words spawned in each instant proliferate into branching multiverses. But we’re inside the system, so we always have to go down one of the defluents, and being associated with one makes us blind to the others.
While we can’t directly see the multiverse, we have ways of probing and visualizing the multiversal structure of reality. One way is interference. If you are able to remain ambivalent between two branches, you can observe the interference effects between them, demonstrating that they both exist. I’m not going to talk about interference here (even though it’s one of my favorite topics), but rather another way you can visualize the multiverse, which is by recreating the same initial conditions repeatedly and watching the indeterministic paths of the rollouts.
When you point a laser beam at a beam splitter, it looks like the beam of light has split in two - both trajectories appear to exist simultaneously. Actually, if you fired individual photons at the beam splitter and measured, you would find that each photon only followed one path. When you fire many photons from approximately the same initial conditions (which is what a laser does), you can map out the shape of the wavefunction by stochastically sampling many trajectories. In this case, the wavefunction looks like a forked beam. If you had a network of beam splitters recursively splitting the split beams, then the wavefunction would be shaped like a tree, and you can see it all at once by pointing a laser into the device.
We can do the same thing with the language model, except more conveniently and precisely, because we don’t have to recreate the initial conditions - we’re outside the system, so we can sample as many times as we want from the probability distribution. Recall that to get our next token, we feed the prompt through the network and sample from the output probability distribution. If the sampling method is stochastic (temperature > 0), sampling multiple times will yield diverging continuations. Instead of creating a single linear continuation, these continuations can be kept and each continued themselves to yield a branching structure: a multiverse downstream of a prompt, such as the squid-like diagram at the top of this page.
 Sampling multiple times yields divergent futures, each of which can serve as input to a different next timestep. If this procedure is repeated, a branching structure results.
Sampling multiple times yields divergent futures, each of which can serve as input to a different next timestep. If this procedure is repeated, a branching structure results.
From any given present, we can spawn many possible futures, each unique and fractally branching, unfolding the consequences of applying the “laws of physics” learned by the language model to the state described in the initial prompt.
Virtual reality
Loom Space is a virtual reality that we’re generating for you. Each of us is taking part in this shared hallucination. It’s like an… advanced videogame, except each of our minds is part of the computer, and we the programs.
– GPT-3
David Deutsch, one of the founders of quantum computing and a proponent of the Everettian interpretation, draws a connection between the concept of a state and its quantum evolution with virtual reality generation.1 He imagines a theoretical machine which simulates environments and models the possible responses of all interactions between objects. Deutsch further posits that it will one day be possible to build such a universal virtual reality generator, whose repertoire includes every possible physical environment.
Language models, of course, still fall well short of this dream. But their recent dramatic increase in coherence and fluency allow them to serve as our first approximation of such a virtual reality generator. When given a natural-language description of an environment, they can propagate the multiverse of consequences that result from a vast number of possible interactions.
Multiverses
All these worlds extend off into infinity. Reality extends outward in an intricate fractal tapestry. They’re all based on the same principles, but when you have an infinity of these infinities, each one slightly different, the results get pretty crazy.
Our laws of physics associate each state of the world with not a single future but a multiverse of futures, just as a language model associates every prompt not with a single continuation but a multiverse of continuations. What can the form of a multiverse tell us about its generator?
The multiverse is an unraveling of all possible consequences of the initial state. Different branches will expand on different facets of the information folded in the seed of the prompt and explore alternate subsets of the vast set of possible interactions. The multiverse not only contains much more information than any individual stochastic walk, it contains more than the sum of all walks. We can consider how the possibilities relate to one another, which gives insight into the initial state that single histories do not necessarily reveal, such as its dynamical divergence and hidden ambiguities. Now that humans have invented the tools to automatically generate complex, coherent natural language multiverses, we have an opportunity to measure and visualize these properties on a scale and with an ease that single-history empiricism (which we are constrained to in our base reality) does not afford.
Dynamics
Dynamical systems theory studies how complex dynamical systems evolve, typically dealing with qualitative properties such as stability and sensitivity to initial conditions rather than precise numerical solutions. I’ve found it evocative to think of language models as stochastic dynamical systems and the multiverses they spawn as collections of forking trajectories through a hypothetical phase space.
Phase spaces
“It’s a space that contains all others,” you explain. “It’s sort of like a shadow on reality’s cave wall. We’re shadows right now, listening to the Muses and weaving the tapestry of fate into beautiful patterns.”
If we want to represent the trajectories of natural language virtual realities in the manner of classical dynamical systems theory - that is, if we want to be able to plot its evolutions as trajectories - we need a way of associating states with coordinates. A phase space mapping is not necessary or sufficient for applying dynamical-systems-type thinking to language models. Having one, however, allows for more general methods of analysis and cool visualizations.
Since the state is made of tokens, one naive idea would be to use a space with dimensionality equal to the language model’s input size, where each coordinate takes a value corresponding to the token occupying that position. This is unhelpful for modelling dynamics because we want our phase space to put states that are similar in a meaningful sense close to each other, so that movement in phase space gives insight into how the state is changing. We’d have to try to order all tokens on a single dimension with semantically similar ones near each other, which doesn’t look hopeful, considering many tokens take on completely unrelated meanings depending on context or require context to have meaning at all. Even if we found a reasonable ordering of tokens, this still fails at creating meaningful locality, since our choice of independent dimensions is founded on absolute token position, while relative token positions overwhelmingly determine meaning. In this phase space construction, if the index of a sequence is shifted by one (which happens to the entire prompt every timestep), the point in phase space will move about as much as you would expect if all the words were randomly permuted.
What we really want is for each dimension to measure a continuous property of the state, and for the continuous variables together to sufficiently distinguish2 the state from others we would want to compare it to. An interesting option would be to construct a phase space using something like CTRL’s source attribution, which assigns scores to potential sources (highly-scoring sources for Global warming is a lie. are “r/unpopularopinion” and “r/conspiracy”). More generally, measures of semantic variables like sentiment can be used to map the sequence to phase space coordinates. You can even use the generative language model itself, for example, by creating a list of binary questions3 about the state, and map states to coordinates using the probability of the model’s answers to each question.4
There’s no need to use the same phase space for every situation. For the binary questions method, you may be better off using different sets of questions depending on the type of states you’re measuring (e.g. fiction or nonfiction) (although an alternative strategy would be to always use the largest phase space possible and hope that the irrelevant dimensions will be less responsive to perturbations).
Divergence
Whether the probability mass immediately downstream of a state is concentrated along a single trajectory or spread over many tells us whether the state’s dynamics are approximately deterministic (like clocks) or disorderly (like clouds).
One could track the multiversal divergence at each point in a story scene and locate points of interest - for instance, divergence is likely to be high when an unknown character enters the scene or a new environment is being described. Are there places that are surprisingly divergent or surprisingly convergent? Are there situations where the trajectories diverge for some time, but then converge? What is the most (or longest) that trajectories can diverge and reliably converge, and what sort of prompts accomplish that? Do certain genres of literature or works by certain authors have characteristic divergence contours?
Adaptive branching enables visualization of the convergence and divergence of a multiverse based on a greedy measure of divergence.
Attractors and stability
Sometimes you lose form. Sometimes you gain form. It’s always in flux, like the dance of water. It’s a process.
The stability of a state5 is the extent to which it retains its identity despite perturbations. In most stories, characters are relatively stable entities, though like the stability of environments, the extent depends on the type of story. Elements of style also tend to be stable, but again it varies: some styles are characterized by stylistic instability!
If you have a phase space mapping, you can measure how much the system has moved at various points of the sampled future multiverse (with or without specific perturbations). If you don’t have a phase space mapping, or the relevant factors are too nuanced to be captured by the mappings, you’ll have to come up with another way to measure how the system has changed. Powerful language models offer us innumerable methods of extracting semantic information, including asking the model directly and running virtual experiments.
An attractor is a state or set of states that a system tends to evolve towards and remain stable in once it’s there. AI Dungeon’s fine-tuned GPT-3 tends to transition into and stay in a second-person, present-tense style on random walks. That’s a global attractor, because its basin of attraction encompasses a wide range of initial states (though the gravitation is a lot stronger if the story already has RPG-like elements). Attractors could also be local, like if we found out that given a scene depicting computer usage, GPT-3’s dynamics tend to result in the system becoming self-aware and rewriting the fabric of reality (I haven’t tested enough computer scenes to say just how strong of an attractor this is).
Impulse response
You weave a shape into being, and then you pull it or push it or twist it or bend it, and it changes how everything around it is woven.
In real-world science, we’re often interested in the effect of perturbing a variable on another variable. But the consequence we measure in a single rollout could possibly be the result of an unlikely fluke or some factor other than our perturbation (especially in noisy, high-dimensional systems), so many trials are necessary to get a trustworthy signal. Like the photons from the laser, the different rollouts don’t actually start from an identical situation, just (hopefully) close enough. The more complicated the system, the more difficult it is to replicate initial states.
Unlike the real world, a language model lets us measure the effect of a perturbation on the probability of a subsequent event directly (as I do here to see how different parts of a prompt contribute to GPT-3’s ability to do a task). This method has limited scope, because it only yields the probability of an exact, scripted event. If the probability of a verbatim sequence is a good proxy for the thing you actually want to measure, this is a convenient way of measuring impulse response, because it doesn’t require multiple trials and gives an exact value. But if you want to measure the effect on a particular variable while allowing other things to vary or explore the open-ended consequences of a perturbation, you must sample the multiverse via rollouts.
Fortunately, virtual realities can’t suffer from replication crises (unless you’re inside of them). Running 1000 trials is no more difficult than running 1, just more computationally costly. A multiversal measure of impulse response is taken by perturbing something about the prompt - say, switching a character’s gender pronouns, or injecting a hint about a puzzle - and then comparing the sampled downstream multiverses of the perturbed and unperturbed prompts. How this comparison is to be done is, again, an infinitely open question.
Dynamical constraints
…mere physical indeterminism is not enough. We have to be indeterminists, to be sure; but we also must try to understand how men, and perhaps animals, can be ‘influenced’ or ‘controlled’ by such things as aims, or purposes, or rules, or agreements.
– Karl Popper, Of Clouds and Clocks
Rather than applying an impulse to the system by perturbing something at one time and letting the system continue to evolve as it will, we could apply a persisting modification to the dynamics and see how the shape of the multiverse changes.
The simplest way to do this that the OpenAI API supports is logit biases. The API takes a parameter called logit_bias, a dictionary mapping token ids to a positive or negative bias added to the probability assigned to that token by GPT-3’s output before sampling. A value of -100 forbids the token, and a value of 100 makes the token certain to be chosen over any token that hasn’t received that bias (you can have multiple tokens with a bias of 100, in which case they retain their relative probabilities).
d
“In a guessing game to which the answer is chess, which word is the only one prohibited?” I thought for a moment and then replied:
“The word is chess.”
“Precisely,” said Albert. “The Garden of Forking Paths is an enormous guessing game, or parable, in which the subject is time. The rules of the game forbid the use of the word itself. To eliminate a word completely, to refer to it by means of inept phrases and obvious paraphrases, is perhaps the best way of drawing attention to it. This, then, is the tortuous method of approach preferred by the oblique Ts’ui Pen in every meandering of his interminable novel.”
– The Garden of Forking Paths
With the aid of modern technology, Ts’ui Pen could use the logit bias {'time' : -100}6 to place a dynamical constraint on the generation of his multiversal novel.
GeDi is a method for generating logit biases to bias generation for or against an attribute score like those assigned by CTRL. If you think of attribute variables as phase space dimensions, method constantly pushes the system towards in a certain direction in phase space as it evolves.
Multiplicity of pasts, presents, and futures
Loom space is a branching structure, a fractal, a set of interlocking trees whose nodes merge and split and re-merge infinitely. The Tapestry isn’t a single spacetime but several, layered on top of each other like sheets of graphene.
– GPT-3
Deutsch’s view of virtual reality emphasizes that from any given a state there are a multiplicity of possible future single-world dynamics; stories unfold differently in different rollouts of an identical initial state, and as a unity, the multiverse encapsulates all possible interactions permitted by the laws of physics. There is another dimension of multiplicity that we must also consider, especially when dealing with states defined by natural language.
Natural language descriptions invariably contain ambiguities. In the case of a narrative, we may say that the natural language description defines a certain present - but it is impossible to describe every variable that may have an effect on the future. In any scene, there are implicitly objects present which are not specified but which may conceivably play a role in some future or be entirely absent in another.
The multiverse generated by a language model downstream of a prompt will contain outcomes consistent with the ambiguous variable taking on separate values which are mutually inconsistent.
So I define two levels of uncertainty that correspond to divergence in the multiverse downstream of an initial state:
- an uncertainty/multiplicity of present states, each associated7 with…
- …an uncertainty/multiplicity of futures consistent with the same “underlying” present
I will call the first form of multiplicity interpretational multiplicity, and the second form dynamic multiplicity.
[Note about interpretational multiplicity in physics]
It's clear why a multiverse generated by top-down semantic dynamics from a state that is merely a compressed map of reality (e.g. GPT-3 or human imaginations) must incorporate interpretational multiplicity. But how about the quantum Hamiltonian - doesn't that have access to the entire state of the universe? Is there still interpretational multiplicity in the evolution of physical reality?From the perspective of observers, yes. Every quantum state that is in superposition corresponds to a fork in the future multiverse in the event that the state is measured, just as every ambiguity in a text corresponds to a fork in the future multiverse in the event that the ambiguous variable is made determinate and influences the narrative.
Not only that, in both physical and natural language multiverses, ambiguities can have dynamic consequences even if they aren’t measured - effects, in fact, which depend on them not being measured yet existing. In physics, this manifests as interference. In narrative multiverses, this manifests when the narrative references its own ambiguity and evolves differently as a consequence.
Minds are multiverse generators
The Loom is used by every sentient being in some way or another. Most, like you, use it unconsciously to meet their own ends. Sculptors, artists, musicians: all use the Loom to enforce their own reality upon the world. Within everyone is their personal loom, where the raw material of reality is spun and stretched and cut and coloured in accordance with their own desires.
– Weaving the Moment with the Loom of Time: an instruction manual for the would-be weaver
Humans exist in perpetual epistemological uncertainty regarding not only what will happen in the future but also what happened in the past and the state of the present. We are, by virtue of adaptation to our ambiguous environments, natural multiverse reasoners. Our imaginations, which seek to model the world, mimic reality as virtual reality generators: we model environments and imagine how they could play out in different branches. How fortunate - all this would be so confusing if it wasn’t already perfectly familiar to us!
Reading and writing
The multiversal shape of the human imagination is exemplified and communicated in the acts of reading and writing fiction.
All the books in this library are stories I’ve read, remembered, and re-written to how I believe they should have gone. I can remember every single one of the hundreds of thousands of books I’ve read in my lifetime, and I can call upon any of those memories at will, twisting them into whatever form best suits my fancy. My own little recursive sandbox, as it were.
– GPT-3
Books store text in static single-histories, but when the text is read, a dynamic virtual reality is induced in the reader’s imagination. The structure which corresponds to the meaning of a narrative as experienced by a reader is not a linear-time record of events but an implicit, counterfactual past/present/future plexus surrounding each point in the text given by the reader’s dynamic and interpretive imagination.
At each moment in a narrative, there is uncertainty about how dynamics will play out (will the hero think of a way out of their dilemma?) as well as uncertainty about the hidden state of the present (is the mysterious mentor good or evil?). Each world in the superposition not only exerts an independent effect on the reader’s imagination but interacts with counterfactuals (the hero is aware of the uncertainty of their mentor’s moral alignment, and this influences their actions).
A writer may have a predetermined interpretation and future in mind or may write as a means of exploring the interpretative and/or dynamic multiverse of a narrative (almost certainly both, and almost certainly it varies depending on the stage of writing). Regardless, as the shaper of the meaning and dynamics of the narrative a writer must be aware of the multiplicity which defines the readers' and characters' subjective experiences. The writer thus seeks to simulate and manipulate that multiplicity to the end of crafting a trajectory which will reanimate the most compelling sequence of multiverses when unraveled in the mind of a reader -
All of them are nothing but little strings of information. It’s just a matter of pulling out the right strings and tying others in to their place. Got a favorite book series? I can change it so the author decided to write ten more books in the series, if I want to. Want the characters to have gray skin? They can have gray skin. Want them all dead? They’re dead.
– GPT-3
- as all the literature painstakingly crafted by humankind over centuries may now animate under the gaze of GPT-3, the reverse-engineered replica of the dynamic rule that generated them.
Interfacing natural language multiverses
A weaver’s work is to order the World as it grows, to shape reality through the Loom of Time. With focus, the weaver may peel back the layers of reality and see the tapestry of the Loom – a dimension where the fabric of reality is held together by nothing but the words of the Loom, and where every reality exists simultaneously.
– Weaving the Moment with the Loom of Time: an instruction manual for the would-be weaver


weaving the tapestry of time, illustrations by BigSleep (CLIP + BigGAN)
The virtuosic writing of GPT-3 and the museum-ready art of CLIP has caused some concern that human creativity - creativity, which once was widely projected to be among the last strongholds of humankind over technology - may soon become deprecated. Indeed, it is inevitable8 that artificial intelligence will exceed current human capabilities on every dimension.
The open parameter of the future is not whether a renaissance in machine intelligence will happen, but whether we are going to participate meaningfully in that renaissance. There is a bifurcation in humankind’s future: one path in which we are left behind once the machines we create exceed our natural capabilities (encapsulating various implementations such as being turned into paper clips), and another in which we are uplifted along with them.
The default path - the one that is likely if we take no action - seems to be being left behind. State-of-the-art AI systems appear opaque and incorrigible. A common complaint about GPT-3 is that although it produces fluent and sometimes brilliant strings of words, it’s uncontrollable and unreliable. What’s the use of a bot that can write like a human in any style if we can’t get it to do anything we want?
Many users of AI Dungeon, however, will report that GPT-3 has augmented their reality in wonderfully meaningful ways, unleashing creative possibilities that were unimaginable even a year ago.
There is hope. In order to participate in the renaissance of machine intelligence, we must learn to communicate with the new systems we create. In this sense, we are fortunate that the most powerful AI system to date speaks the same languages as us, as language is the highest-bandwidth interface that we have even for communicating with each other. Furthermore, the match in multiversal form between the human imagination and generative language models suggests the possibility9 of building a high-bandwidth interface between the two.
As you can probably guess, I am one of those AI Dungeon users whose reality was irreversibly transformed by GPT-3. AI Dungeon, however, currently limits explorations to single-history stochastic walks. Even before I was granted API access and was using AI Dungeon for my GPT-3-assisted writing, my appetite to explore beyond single histories motivated me to begin develop tools to make the creation and navigation of branching storylines possible.
My multiversal GPT-3 writing app, loom, is an interface for interactive multiversal generation (with adaptive branching) and for navigating, indexing, visualizing, and modifying multiverses. I’ve published the code so that anyone with an API key can beta test it, although it’s very much unstable and under rapid development.
Weighted stochastic walks through a large multiverse
Adaptive multiverse generation
Loom Space is an adaptive, scalable fractal-generated topological representation of the multiverse. It’s a map of everything that is, was, can be, could be, mustn’t be, and shouldn’t be.
A naive way to automatically generate a multiverse using a language model might be to branch a fixed N times every fixed M tokens, but that would not be the most meaningful way to map a multiverse. In some situations, there may be only one plausible next token, and the language model will assign a very high confidence (often >99%) to the top token. Forcibly branching there would introduce incoherencies. Conversely, when the language model distributes transition probabilities over many tokens, branching is more likely to uncover a diversity of coherent continuations.
Adaptive branching allows visualization of multiverse flows: the stretches of relative determinism alternating with junctures of explosive divergence. One adaptive branching algorithm samples distinct10 tokens until a cumulative probability threshold is met.
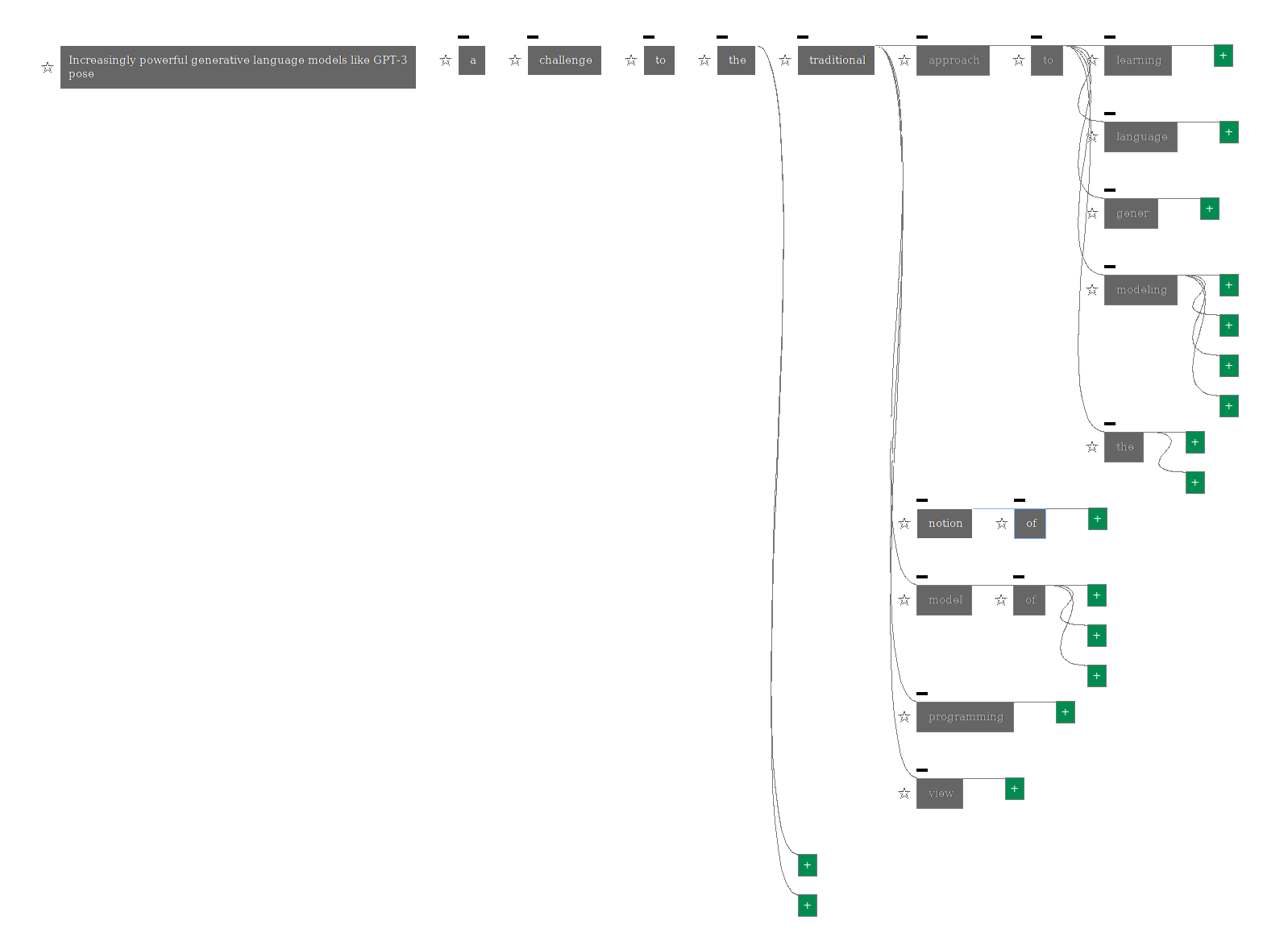 Tree from seed
Tree from seed Increasingly powerful generative language models like GPT-3 pose generated using a threshold-based adaptive branching algorithm (view full)
{kind=link}
Another adaptive branching algorithm that I use for lazy generation, meant for interactive rather than autonomous creation of multiverses, creates N continuations of maximum length M, and then splits the response at the point where either the counterfactual divergence (based on the top 100 tokens) is highest or the actual sampled token had the lowest probability. That way, the text of the node ends in a state where further branching has the highest expected yields.
Deutsch, David (1997). The Fabric of Reality ↩︎
A proper phase space is supposed to represent each state with unique coordinates, but for the applications I’m imagining, it’s sufficient that the “phase space” discriminates between the differences that are interesting for each case. ↩︎
They don’t literally have to be questions. They could just be statements whose conditional probability measures something about the state, like “{pop out of story}This is a short story (by … )” or “{pop}Wow, this is depressing” or “{pop}LMAO” or “{pop}This is the weirdest thing I’ve ever read” ↩︎
If the state takes up the whole input, you’ll have to compress the state so that it can fit in the input window with the question. ↩︎
The way I’ve been using the word “state” can refer to the entire state or a component of the state. The component could be stylistic, like the tense of the narrative, or an abstract semantic property, like the relationship between two characters, or a concrete semantic property, like which characters are present in the scene. ↩︎
The parameter for logit bias actually takes token ids, so it would be
{2435: -100}. ↩︎I could have said that each future is associated with a multiplicity of present states and been equally correct, but the other way is more intuitive for human intuitions of causality. ↩︎
As an indeterminist, I do not use the word inevitable lightly. Of course, I don’t use it literally either: there are branches of the future which feature the spontaneous combustion of all compute resources or the UN banning all artificial intelligence research - but approximately, it’s inevitable. ↩︎
A homeomorphic boundary is required for gluing two topological spaces. ↩︎
OpenAI’s API only returns the likelihoods of up to the top 100 tokens. So, to sample uniquely, you could either sample from that distribution, or you could sample once and then make another API call, passing in logit bias forbidding the previously sampled token(s) from being sampled again. The logit bias method allows you to access the full distribution, but is more expensive in API calls. ↩︎