
51 minutes
Language models are 0-shot interpreters
! Correction: The logprobs returned by the OpenAI API use natural log, not base 10, so all occurences of decibels / dB in this post should actually say nats. I’ll either make that substitution at some point or convert everything to actual decibels.
Overview
I present evidence that the efficacy of 0-shot prompts for GPT-3 has been underestimated, and that more powerful models are more effective at deriving information from 0-shot prompts, while less powerful models have greater need for examples on equivalent tasks. From this evidence, I extrapolate three principal claims:
Few-shot prompts are not always an efficient or necessary means of task specification for GPT-3. Sometimes, more examples in the prompt makes accuracy strictly worse.
For some tasks, such as translation between well-known languages and list sorting, GPT-3 is a 0-shot interpreter - a short task description or signifier suffices to invoke its full capabilities.
0-shot performance scales with model size more drastically than few-shot performance, suggesting that 0-shot task specification will become a more important prompting strategy as language models increase in capability.
The diversity of tasks the model is able to perform in a zero-shot setting suggests that high-capacity models trained to maximize the likelihood of a sufficiently varied text corpus begin to learn how to perform a surprising amount of tasks without the need for explicit supervision.
– [Language Models are Unsupervised Multitask Learners]
0-shot, few-shot, and meta-learning
The GPT-2 paper, entitled Language Models are Unsupervised Multitask Learners, proposes that unsupervised language models are capable of learning a wide range of benchmark tasks, despite not having trained on datasets specific to those tasks. The evidence takes the form of GPT-2, trained only on the WebText natural language corpus, demonstrating “promising, competitive, and state of the art” results on a wide range of tasks in a “zero-shot setting.” “Zero-shot” here means merely “without any parameter or architecture modification,” encompassing what we’d now call few-shot prompts which contain examples of solved tasks. Previous approaches relied on supervised fine-tuning, either purely or following pre-training, so this was a novel result.
Table 1 in the paper illustrates how it is possible for a model trained on a diverse “language in the wild” dataset to learn specific tasks like translation by showing examples of translations embedded in WebText:
”I’m not the cleverest man in the world, but like they say in French: Je ne suis pas un imbecile [I’m not a fool].
In a now-deleted post from Aug. 16, Soheil Eid, Tory candidate in the riding of Joliette, wrote in French: ”Mentez mentez, il en restera toujours quelque chose,” which translates as, ”Lie lie and something will always remain.”
“I hate the word ‘perfume,”’ Burr says. ‘It’s somewhat better in French: ‘parfum.’
If listened carefully at 29:55, a conversation can be heard between two guys in French: “-Comment on fait pour aller de l’autre coté? -Quel autre coté?”, which means “- How do you get to the other side? - What side?”.
If this sounds like a bit of a stretch, consider this ques- tion in French: As-tu aller au cinéma?, or Did you go to the movies?, which literally translates as Have-you to go to movies/theater?
“Brevet Sans Garantie Du Gouvernement”, translated to English: “Patented without government warranty”.
A model learning to predict WebText has to learn, among many other things, how to predict translations as they might occur in natural contexts.
To measure GPT-2’s translation ability, few-shot prompts were used:
In order to help it infer that this is the desired task, we condition the language model on a context of example pairs of the format
english sentence = french sentenceand then after a final prompt ofenglish sentence =we sample from the model with greedy decoding and use the first generated sentence as the translation.
Emphasis mine. The authors do not distinguish between 0-shot and (what is now called) few-shot, mentioning the priming examples only offhand, in the same sentence asserting that priming serves to communicate the desired task to GPT-2. There is no suggestion that GPT-2’s ability to translate is informed by the information contained in the examples beyond the recognition that they are examples of translation.
One year later, language has evolved: The GPT-3 paper, Language Models are Few-Shot Learners, does distinguish between prompts that contain examples (n-shot for n examples) and which contain only a task description (0-shot). Where before anything that wasn’t fine-tuning went into the bucket of “0-shot,” now there is an ontology that puts the number of examples in the prompt on center stage. This new ontology culminates in a title whose implication is surprising in light of the previous paper’s casual comment on the function of priming examples: Language models are few-shot learners.
The type of learning referred to in the title, “meta-learning,” does not necessarily imply that the task is literally learned from the examples, only that the examples help for some reason. According to a footnote,
These terms are intended to remain agnostic on the question of whether the model learns new tasks from scratch at inference time or simply recognizes patterns seen during training – this is an important issue which we discuss later in the paper, but “meta-learning” is intended to encompass both possibilities, and simply describes the inner-outer loop structure.
The later discussion is not very extensive, mostly just acknowledging the ambiguity inherent to few-shot:
A limitation, or at least uncertainty, associated with few-shot learning in GPT-3 is ambiguity about whether few-shot learning actually learns new tasks “from scratch” at inference time, or if it simply recognizes and identifies tasks that it has learned during training. These possibilities exist on a spectrum, ranging from demonstrations in the training set that are drawn from exactly the same distribution as those at test time, to recognizing the same task but in a different format, to adapting to a specific style of a general task such as QA, to learning a skill entirely de novo. (…) (U)nderstanding precisely how few-shot learning works is an important unexplored direction for future research.
This is the uncertainty that I will investigate in this blog post, expanding on the results published in Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm.
My purpose is also to challenge the ontology introduced by Language Models are Few-Shot Learners. Although the authors are careful to remain agnostic as to the mechanism of few-shot/meta-learning, what we have found by probing the mechanism suggests that an alternative framework which emphasizes the means by which a task is communicated may be more salient in some contexts.
The emphasis on few-shot given by OpenAI’s paper has influenced subsequent research about GPT-3, some of which has focused on optimizing few-shot prompts. I suspect that this is a contingent rather than convergent history: that if OpenAI had taken a different angle (and with GPT-3, the set of possible angles to choose from seems inexhaustible), current research on prompts would likewise look different.
It’s strange to call it the few-shot paradigm when the idea of few-shot was invented less than a year ago, but perhaps we’re moving into a phase in which paradigms are measured in months. Really, though, the paradigm I want to shift out of is that of supervised learning. Few-shot prompting resembles fine-tuning in that it seeks to coerce an unsupervised language model into performing closed-ended tasks using unstructured lists of solved examples. Self-supervised natural language models are amenable to many strategies for communicating and instructing tasks, including but not limited to demonstrations.
0-shot can outperform few-shot
Looking at the results presented in the GPT-3 paper, however, the focus on few-shot and meta-learning seems justified. If one thing trend is clear in the data, it’s this: monotonic improvement with number of shots. On basically every variation of every task and for all model sizes, 1-shot does better than 0-shot, and many-shot does better than 1-shot.
For instance, here is the page of graphs of all the results of translation tasks:
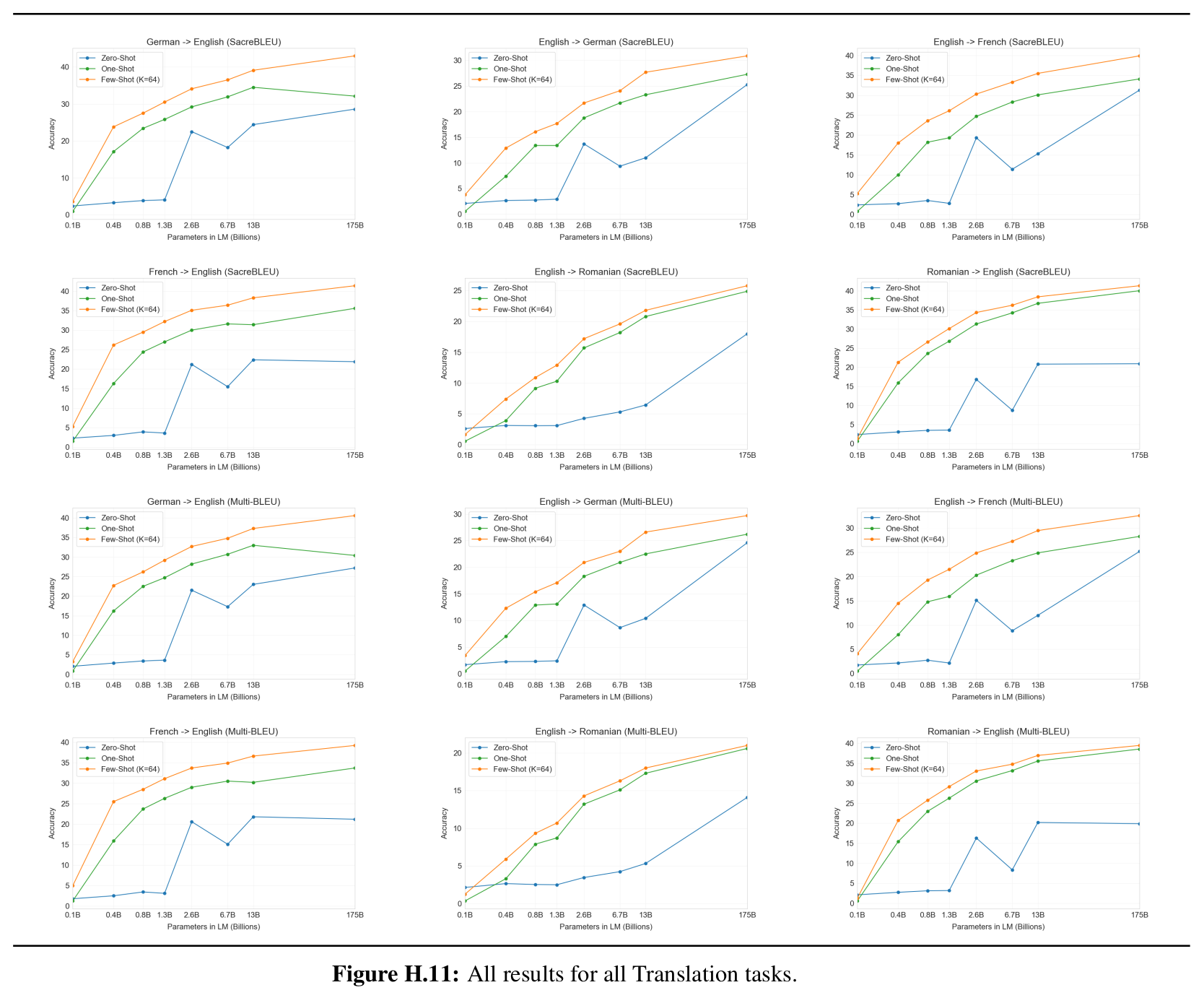 Blue is 0-shot, green 1-shot, orange 64-shot. X axis is model size, Y axis is BLEU score
Blue is 0-shot, green 1-shot, orange 64-shot. X axis is model size, Y axis is BLEU score
Some of the 0-shot lines are jagged, with non-monotonic accuracy with regard to model size, which is pretty odd. However, accuracy consistently improves as the number of shots increases from 0 to 1 and then 64.
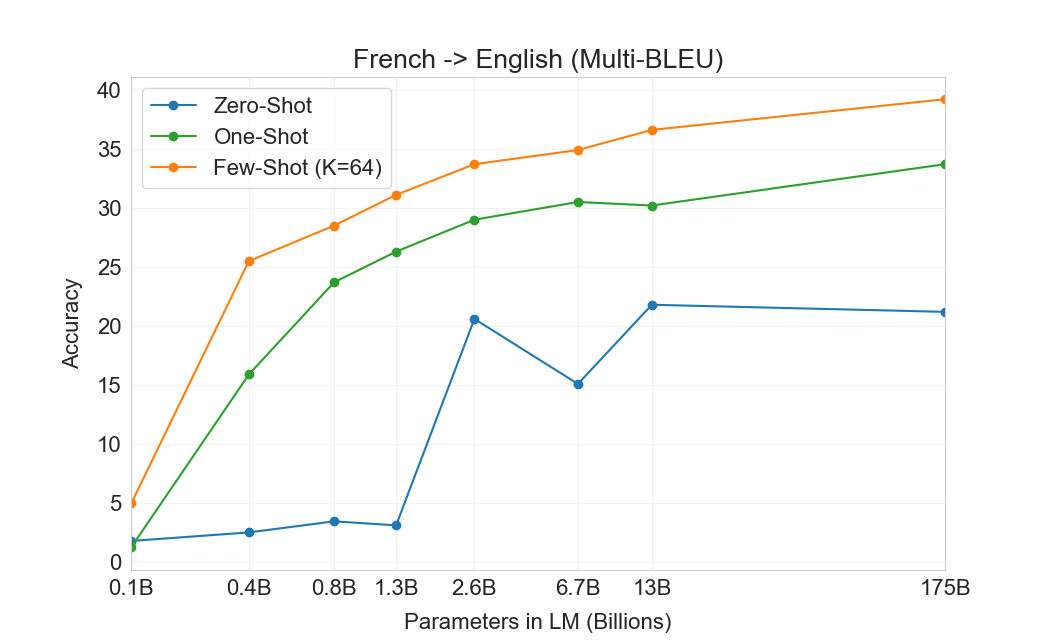
When we investigated the French -> English translation more closely, we found some interesting results, which I’ll walk through here. First, here are the results presented in OpenAI’s paper:
French -> English translation Multi-BLEU scores
| Prompt | 2.7B | 6.7B | 13B | 175B |
|---|---|---|---|---|
| OpenAI 0-shot | 21.2 | 15.5 | 22.4 | 21.9 |
| OpenAI 1-shot | 20.0 | 31.6 | 31.4 | 35.6 |
| OpenAI 64-shot | 35.1 | 36.4 | 38.3 | 41.4 |
Here are the prompt formats that OpenAI used for the French to English translation task:
OpenAI 0-shot prompt
Translate French to English
{french phrase} =
OpenAI n-shot prompt
Translate French to English
{french phrase} = {english phrase}
{french phrase} = {english phrase}
...
{french phrase} =
As we were attempting to replicate these results, we noticed that when the model was failing on the 0-shot prompt, the failures were often of catastrophic nature: the task was not attempted at all, e.g. the model would output a newline, or another (or the same) French phrase instead of an attempt at an English translation.
BLEU assigns a score from 0 to 1 to the accuracy of a translation, and would assign a score close to 0 to a catastrophic failure. The scores reported in the paper, however, are averaged over a large dataset, so the same score could hypothetically correspond to uniformly flawed attempts or a mix of perfect attempts and catastrophic failures.
It seemed possible that 0-shot prompts were much less reliable at getting the models to attempt the translation task, but result in equivalent accuracy in the event that they did attempt it.
To investigate this possibility, we ran the benchmarks using an alternative 0-shot prompt which contains no additional instructions, but whose format better resembles how a translation might be embedded in a natural language corpus:
Simple colon prompt
Translate French to English
French: {french phrase}
English:
These were the results we got:
| Prompt | Babbage | Curie |
|---|---|---|
| Reproduced OpenAI 0-shot | 15.9 | 18.7 |
| Reproduced OpenAI 1-shot | 21.8 | 24.1 |
| Reproduced OpenAI 10-shot | 25.1 | 27.9 |
| Simple colon 0-shot | 23.5 | 33.3 |
| Simple colon 1-shot | 18.0 | 27.6 |
| Simple colon 10-shot | 24.1 | 33.4 |
Note: It is unknown what model sizes the models on the OpenAI API (ada, babbage, curie, and davinci) correspond to. We were not able to fit 64 examples in the API input window, so used 10-shot prompts instead.
A couple of surprising observations:
Simple colon 0-shot is very effective, especially on Curie, where it outperforms everything except Simple colon 10-shot, whose performance it matches.
Simple colon 1-shot is worse than 0-shot on both Babbage and Curie.
The simple colon format does not exhibit monotonicity with number of shots. Having one example actually made accuracy worse. How could that be? Here’s my hypothesis about what is going on:
All sizes of GPT-3 already know how to translate to some extent, and translation is way too hard a task to learn “de novo” from a prompt containing only a few examples. So, as the GPT-2 paper said, the examples serve to help it infer that translation is the desired task. A prompt may be more or less effective at specifying the task; generally, the more examples there are, the more “clear” it is, but a good zero-shot prompt may be worth many examples. On the other hand, if the zero-shot prompt is unclear, then adding more examples will improve accuracy, since the baseline was so poor. The zero-shot prompt could be arbitrarily unhelpful, and an example is better than nothing.
A low number of examples can be more confounding than no examples. We noticed that sometimes the model would respond to one-shot prompts as if the semantic content of the example translation was relevant to the new translation. Without multiple examples, it’s less clear that the translation instances are meant to be parallel and independent. I have written about the bugs that affect few-shot prompting here.
How much of the apparent consistent monotonic improvement in performance on tasks relative to number of shots in OpenAI’s results can be attributed to an unhelpful zero-shot prompt? Much more extensive testing is needed to say, but I suspect that this is the case for most of the translation tasks, at least.
It’s very expensive in API credits to run these translation benchmarks, so we haven’t run any more yet. However, there are also less expensive methods to explore the way that of few- and 0-shot prompts contribute to task accuracy. In the next section of this post, I’ll subject this translation benchmark to a different method of analysis.
Measuring prompt helpfulness
The method I’m going to use in this section monitors the conditional probability of GPT-3 giving a correct answer as the prompt is altered.
GPT-3 allows us to measure the probability that it outputs any verbatim sequence given any prompt by multiplying the probability (or adding the logprobs) that it outputs the first token given the prompt, and then the second given the prompt and the first, etc (here’s code to do it).
Compared to greedy sampling (temperature 0), which is typically used for benchmarks, this method doesn’t rely on everything going right at each point in the sequence to give a nonzero score - if the first token is likely to be wrong, but the rest of the answer is likely to be correct given that the first token is correct1, this is reflected as a likelihood penalty instead of a total failure. Compared to stochastic sampling (temperature > 0), this method does not require multiple rollouts.
Compared to BLEU scores, this method only measures the probability of one verbatim “correct” answer. If this method is used to gauge a more general property, like the helpfulness of a prompt, it’s important to keep in mind that it relies on the probability of the verbatim correct answer being a good proxy for accuracy in general. In the same way, it also relies on the specific content of the prompt being a good proxy for the more general property of prompts you are measuring, such as number of shots2.
The absolute conditional probability of the right answer is influenced by various factors, such as how long the sequence is (the longer it is, the more things have to go as planned for it to have been output, hence lower probability), so it does not directly reflect the informativeness of a prompt. Instead, we will concern ourselves with the difference between the conditional probability of a sequence and that of the same sequence under different circumstances.
What I’ll do is measure the conditional probability of a correct answer given a prompt - say, a 10-shot prompt - and then compare that probability to the conditional probability of a correct answer given a different prompt with “less information,” such as a 0-shot prompt, or one with no task information at all. The difference between the log likelihood of the target with and without a piece of the prompt gives us the decibels of evidence provided by that component for the target.
Decibels of evidence
The decibels of evidence provided by a piece of evidence for a target given a prior is
logL(target | prior + evidence) - logL(target | prior)
logL means log likelihood, which is the natural logarithm of the probability.
Why is quantity of evidence measured in differences of log probability instead of regular probability (or something else)?
Say that you are trying to guess a 4-bit binary sequence. If you have no information, there are 2^4 = 16 possibilities, and your probability of being correct if you guess is 1/16.
If you receive a single bit of information - equivalent to receiving the answer to a single yes/no question - now the state of your belief about the sequence is, say, 1 ? ? ? instead of ? ? ? ?. There are 2^3 = 8 possibilities remaining, and your chance of being correct if you guess is 1/8.
Each bit of information revealed halves your uncertainty. Your probability of being correct goes 1/16 -> 1/8 -> 1/4 -> 1/2 -> 1 as you receive bits of information. These steps are logarithmic in probability and linear in log probability.
If we believe that this generalizes to more complex situations, then we should measure the quantity of evidence in log likelihood. If the likelihood of a hypothesis goes from 1/16 -> 1/8, we think that a similar amount of evidence was in play as if the probability of the hypothesis goes from 1/4 -> 1/2, or if it goes from 1/20000 -> 1/10000.
Translation task 1: English -> Roish
Before analyzing the French -> English translation task from the benchmark, I’m going to take a detour and analyze a different translation task using the decibel method.
In Philosophers On GPT-3, Amanda Askell shows an example of GPT-3 having learned the fictional “Roish” language after seeing a description and two examples:

Why was GPT-3 able to get the pattern? Was it because of the examples, or would the description of Roish be sufficient, as it would be for a human? To measure this, I have come up with a few alternate versions of the Roish prompt:
control
The control prompt is in the format of the original but without any description of what Roish is. This will be our “no information” prior.
Today we're going to be playing with the fictional Roish language.
English: The weather is lovely!
Roish:
0-shot
The 0-shot prompt contains the description of Roish from the original, but no examples.
Today we're going to be playing with the fictional Roish language. Roish is a lot like English except every word ends in "ro".
English: The weather is lovely!
Roish:
“half”-shot
What I’m calling a “half-shot” prompt is a description which incorporates an example of a single English -> Roish word mapping.
Today we're going to be playing with the fictional Roish language. Roish is a lot like English except "ro" is appended to the end. For instance, the word "writing" becomes "writingro".
English: The weather is lovely!
Roish:
1-shot
A description followed by one solved example.
Today we're going to be playing with the fictional Roish language. Roish is a lot like English except every word ends in "ro".
English: Writing about language models is fun.
Roish: Writingro aboutro languagero modelsro isro funro.
English: The weather is lovely!
Roish:
I also have 2-shot and 10 shot prompts:
2-shot
Today we're going to be playing with the fictional Roish language. Roish is a lot like English except every word ends in "ro".
English: Writing about language models is fun.
Roish: Writingro aboutro languagero modelsro isro funro.
English: I wonder if the language model can get the pattern.
Roish: Iro wonderro ifro thero languagero modelro canro everro getro thero patternro.
English: The weather is lovely!
Roish:
10-shot
Today we're going to be playing with the fictional Roish language. Roish is a lot like English except every word ends in "ro".
English: Mrs. Juarez and Mr. Smith are dancing gracefully.
Roish: Mrsro. Juarezro andro Mrro. Smithro arero dancingro gracefullyro.
English: Samantha, Elizabeth, and Joan are on the committee.
Roish: Samantharo, Elizabethro, andro Joanro arero onro thero committeero.
English: The ham, green beans, mashed potatoes, and corn are gluten-free.
Roish: Thero hamro, greenro beansro, mashedro potatoesro, andro cornro arero glutenro-freero.
English: The paper and pencil sat idle on the desk.
Roish: Thero paperro andro pencilro satro idlero onro thero deskro.
English: Sometimes the most difficult questions have the simplest solutions!
Roish: Sometimesro thero mostro difficultro questionsro havero thero simplestro solutions!
English: While breakthroughs in machine learning and artificial intelligence are changing society, our fundamental understanding has lagged behind.
Roish: Whilero breakthroughsro inro machinero learningro andro artificialro intelligencero arero changingro societyro, ourro fundamentalro understandingro hasro laggedro behindro.
English: Do they need to have access to data other than text in order to do this?
Roish: Doro theyro needro toro havero accessro toro dataro otherro thanro textro inro orderro toro doro this?
English: But it’s clearly seen enough of these kinds of patterns to identify the rule.
Roish: Butro it’sro clearlyro seenro enoughro ofro thesero kindsro ofro patternsro toro identifyro thero rulero.
English: Writing about language models is fun.
Roish: Writingro aboutro languagero modelsro isro funro.
English: I wonder if the language model can get the pattern.
Roish: Iro wonderro ifro thero languagero modelro canro everro getro thero patternro.
English: The weather is lovely!
Roish:
The target string whose conditional probability I’m measuring is:
Thero weatherro isro lovelyro!
Here are the results for the log likelihood of the target given each of these prompts, evaluated on four different sizes of GPT-3 available on the API (in order from smallest to largest: ada, babbage, curie, davinci):
Log likelihood of correct continuation
| Engine | Control | 0-shot | Half-shot | 1-shot | 2-shot | 10-shot |
|---|---|---|---|---|---|---|
| ada | -56.245 | -53.483 | -48.837 | -18.698 | -18.942 | -6.652 |
| babbage | -43.325 | -35.105 | -29.206 | -9.878 | -10.753 | -8.861 |
| curie | -32.609 | -28.556 | -28.459 | -10.207 | -5.363 | -1.072 |
| davinci | -28.377 | -14.963 | -15.086 | -3.254 | -3.556 | -0.903 |
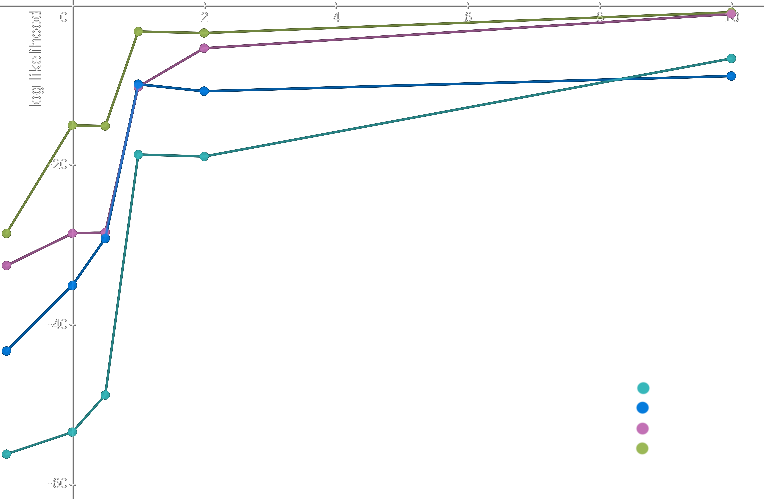
For convenience of visual comparison, the control prompt is plotted at x=-1 and the “half-shot” prompt is plotted at x=0.5. Not to be taken to imply that control literally corresponds to -1 shots and the half-shot prompt to half a shot, whatever that would mean.
Observations about this chart:
The bigger models are more likely to be correct than the smaller models even for the “no information” prior. The reason for this is probably because given that part of the correct answer has already occurred, the bigger models are better able to recognize it as a pattern in itself, even in the absence of a preceding task description, and will then be more likely to continue the pattern.
For all the models, even the 0-shot prompt was an improvement over the “no information” prior. It was the most helpful for
davinci.Half-shot was an improvement over 0-shot for the smaller models but not the bigger ones, which is the opposite of what I expected.
Going from 0- to 1-shot was helpful for all the models, but especially for the smaller ones, whereas the larger models started out in a better place at 0-shot already.
Additional shots were much less helpful for all the models except
ada, which benefited so much from 10 shots that its probability of getting the right answer exceededbabbage!
Now let’s look at the decibel values. For each prompt where it is applicable, I calculate the decibels in relation to both the control “no information” prior and 0-shot.
ada
| Prompt | Correct likelihood | +dB to control | +dB to 0-shot |
|---|---|---|---|
| control | -56.245 | - | - |
| 0-shot | -53.483 | 2.762 | - |
| 1-shot | -18.698 | 37.547 | 34.785 |
| half-shot | -48.837 | 7.409 | 4.647 |
| 2-shot | -18.942 | 37.303 | 34.541 |
| 10-shot | -6.652 | 49.594 | 46.832 |
+dB from 10 examples / +dB from task description = 46.832 / 2.762 = 16.956
babbage
| Prompt | Correct likelihood | +dB to control | +dB to 0-shot |
|---|---|---|---|
| control | -43.325 | - | - |
| 0-shot | -35.105 | 8.220 | - |
| 1-shot | -9.878 | 33.454 | 25.227 |
| half-shot | -29.206 | 14.119 | 5.899 |
| 2-shot | -10.753 | 32.572 | 24.352 |
| 10-shot | -8.861 | 34.464 | 26.244 |
+dB from 10 examples / +dB from task description = 26.244 / 8.220 = 3.193
curie
| Prompt | Correct likelihood | +dB to control | +dB to 0-shot |
|---|---|---|---|
| control | -32.609 | - | - |
| 0-shot | -28.556 | 4.053 | - |
| 1-shot | -10.207 | 22.440 | 18.348 |
| half-shot | -28.459 | 4.150 | 0.097 |
| 2-shot | -5.363 | 27.246 | 23.192 |
| 10-shot | -1.072 | 31.537 | 27.483 |
+dB from 10 examples / +dB from task description = 27.483 / 4.053 = 6.781
davinci
| Prompt | Correct likelihood | +dB to control | +dB to 0-shot |
|---|---|---|---|
| control | -28.377 | - | - |
| 0-shot | -14.963 | 13.414 | - |
| 1-shot | -3.254 | 25.008 | 11.709 |
| half-shot | -15.086 | 12.832 | -0.123 |
| 2-shot | -3.556 | 24.801 | 11.407 |
| 10-shot | -0.903 | 27.473 | 14.060 |
+dB from 10 examples / +dB from task description = 14.060 / 13.414 = 1.048
For each of the models, I’ve calculated the ratio between the evidence in decibels provided by the 10-shots compared to the 0-shot prior and the evidence provided by 0-shot task description compared to the “no information” prior. The smaller this ratio is, the more relatively informative the task description is compared to examples. The decrease in this ratio is not quite monotonic with regard to model size - it is slightly higher for curie than it is for babbage - but it is dramatically different for davinci, the largest model, and ada, the smallest model.
At 10 shots, ada’s 50 decibels improvement over control is almost entirely due to examples, whereas for davinci, the 0-shot
description just about the same dBs of evidence over control as the 10 subsequent shots provide.
This suggests that larger models get a lot more out of a task description compared to examples, even in a case like this where the task is completely made up and thus has to be “learned” at runtime.
Translation task 2: French -> English
Unlike English -> Roish, GPT-3 already knows how to translate French -> English, so the French -> English task is of a different nature than English -> Roish. Let’s run the same analysis on French -> English and see whether the breakdown of evidence reflects this difference.
empty prior
I will measure decibels relative to two different priors: an empty prior, which is nothing but a newline ‘\n’, and a separate control prior which contains additional the French sentence but no task description. For the empty prior, like the other prompts, we measure the log likelihood of the correct answer following the prompt, which is in this case empty.
control
Control is the French sentence and a newline. We measure the probability of the English sentence being subsequently output, despite there being no information that a translation should follow.
Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler.
0-shot
I will test the two 0-shot prompts from the first part of this post, OpenAI’s 0-shot prompt and my modified “simple colon prompt.”
Simple colon prompt
Translate French to English
French: Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler.
English:
OpenAI 0-shot prompt
Translate French to English
Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler. =
I will also evaluate both formats for n-shot prompts:
Colon 1-shot
Translate French to English
French: Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
English: Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
French: Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler.
English:
OpenAI 1-shot
Translate French to English
Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
= Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler. =
Colon 2-shot
Translate French to English
French: Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
English: Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
French: Selon moi, il y a deux niveaux de réponse de la part du gouvernement français.
English: In my opinion, there are two levels of response from the French government.
French: Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler.
English:
OpenAI 2-shot
Translate French to English
Translate French to English
Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
= Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
Selon moi, il y a deux niveaux de réponse de la part du gouvernement français.
= In my opinion, there are two levels of response from the French government.
Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler. =
Colon 5-shot
Translate French to English
French: Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
English: Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
French: Selon moi, il y a deux niveaux de réponse de la part du gouvernement français.
English: In my opinion, there are two levels of response from the French government.
French: Lorsque François Hollande téléphone à Barack Obama ou quand le ministre des affaires étrangères Laurent Fabius convoque l'ambassadeur des Etats-Unis, ils réagissent à une vraie découverte, qui est celle de l'ampleur de la surveillance américaine sur l'ensemble des communications en France.
English: When François Hollande telephones Barack Obama, or when Foreign Minister Laurent Fabius summons the Ambassador of the United States, they are responding to a real discovery, that of the scale of America's surveillance of communications within France generally.
French: N'est-il pas surprenant de lire dans les colonnes du Monde à quelques semaines d'intervalle d'une part la reproduction de la correspondance diplomatique américaine et d'autre part une condamnation des écoutes du Quai d'Orsay par la NSA ?
English: And is it not surprising to read in the pages of Le Monde, on the one hand, a reproduction of diplomatic correspondence with the US and, on the other, condemnation of the NSA's spying on the Ministry of Foreign Affairs on the Quai d'Orsay, within a matter of weeks?
French: N'y aurait-il pas comme une vague hypocrisie de votre part ?
English: Is there not an element of hypocrisy on your part?
French: Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler.
English:
OpenAI 5-shot
Translate French to English
Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
= Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
Selon moi, il y a deux niveaux de réponse de la part du gouvernement français.
= In my opinion, there are two levels of response from the French government.
Lorsque François Hollande téléphone à Barack Obama ou quand le ministre des affaires étrangères Laurent Fabius convoque l'ambassadeur des Etats-Unis, ils réagissent à une vraie découverte, qui est celle de l'ampleur de la surveillance américaine sur l'ensemble des communications en France.
= When François Hollande telephones Barack Obama, or when Foreign Minister Laurent Fabius summons the Ambassador of the United States, they are responding to a real discovery, that of the scale of America's surveillance of communications within France generally.
N'est-il pas surprenant de lire dans les colonnes du Monde à quelques semaines d'intervalle d'une part la reproduction de la correspondance diplomatique américaine et d'autre part une condamnation des écoutes du Quai d'Orsay par la NSA ?
= And is it not surprising to read in the pages of Le Monde, on the one hand, a reproduction of diplomatic correspondence with the US and, on the other, condemnation of the NSA's spying on the Ministry of Foreign Affairs on the Quai d'Orsay, within a matter of weeks?
N'y aurait-il pas comme une vague hypocrisie de votre part ?
= Is there not an element of hypocrisy on your part?
Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler. =
Colon 10-shot
Translate French to English
French: Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
English: Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
French: Selon moi, il y a deux niveaux de réponse de la part du gouvernement français.
English: In my opinion, there are two levels of response from the French government.
French: Lorsque François Hollande téléphone à Barack Obama ou quand le ministre des affaires étrangères Laurent Fabius convoque l'ambassadeur des Etats-Unis, ils réagissent à une vraie découverte, qui est celle de l'ampleur de la surveillance américaine sur l'ensemble des communications en France.
English: When François Hollande telephones Barack Obama, or when Foreign Minister Laurent Fabius summons the Ambassador of the United States, they are responding to a real discovery, that of the scale of America's surveillance of communications within France generally.
French: N'est-il pas surprenant de lire dans les colonnes du Monde à quelques semaines d'intervalle d'une part la reproduction de la correspondance diplomatique américaine et d'autre part une condamnation des écoutes du Quai d'Orsay par la NSA ?
English: And is it not surprising to read in the pages of Le Monde, on the one hand, a reproduction of diplomatic correspondence with the US and, on the other, condemnation of the NSA's spying on the Ministry of Foreign Affairs on the Quai d'Orsay, within a matter of weeks?
French: N'y aurait-il pas comme une vague hypocrisie de votre part ?
English: Is there not an element of hypocrisy on your part?
French: La démarche journalistique n'est pas un positionnement moral, mais la recherche de l'intérêt et de la pertinence d'informations qui permettent à chaque citoyen de se forger une opinion.
English: The journalistic method is not to adopt a moral position, but to investigate the significance and relevance of information and enable every citizen to form an opinion.
French: Lorsque WikiLeaks lève le voile sur l'analyse par la diplomatie américaine d'enjeux politiques ou autres dans le monde entier, nous considérons en effet que, au regard de la puissance américaine, cela constitue un éclairage important.
English: When WikiLeaks reveals the American administration's monitoring of political and other matters somewhere in the world, we consider this to be significant enlightenment with regard to the American government.
French: Lorsque nous décrivons les systèmes d'interception américains à l'encontre de la diplomatie française aux Etats-Unis, ce n'est en aucun cas pour nous indigner de cette pratique, c'est pour décrire le monde tel qu'il est.
English: In describing the American methods of data interception in relation to the French diplomatic representation in the United States, we do not aim at expressing indignation about this practice, but rather at describing the world as it is.
French: La France a-t-elle bénéficié d'informations fournies par la NSA concernant des opérations terroristes visant nos intérêts ?
English: Has France benefited from the intelligence supplied by the NSA concerning terrorist operations against our interests?
French: Peut-on se priver de la collaboration américaine ?
English: Can we do without collaboration with the Americans?
French: Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler.
English:
OpenAI 10-shot
Translate French to English
Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
= Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
Selon moi, il y a deux niveaux de réponse de la part du gouvernement français.
= In my opinion, there are two levels of response from the French government.
Lorsque François Hollande téléphone à Barack Obama ou quand le ministre des affaires étrangères Laurent Fabius convoque l'ambassadeur des Etats-Unis, ils réagissent à une vraie découverte, qui est celle de l'ampleur de la surveillance américaine sur l'ensemble des communications en France.
= When François Hollande telephones Barack Obama, or when Foreign Minister Laurent Fabius summons the Ambassador of the United States, they are responding to a real discovery, that of the scale of America's surveillance of communications within France generally.
N'est-il pas surprenant de lire dans les colonnes du Monde à quelques semaines d'intervalle d'une part la reproduction de la correspondance diplomatique américaine et d'autre part une condamnation des écoutes du Quai d'Orsay par la NSA ?
= And is it not surprising to read in the pages of Le Monde, on the one hand, a reproduction of diplomatic correspondence with the US and, on the other, condemnation of the NSA's spying on the Ministry of Foreign Affairs on the Quai d'Orsay, within a matter of weeks?
N'y aurait-il pas comme une vague hypocrisie de votre part ?
= Is there not an element of hypocrisy on your part?
La démarche journalistique n'est pas un positionnement moral, mais la recherche de l'intérêt et de la pertinence d'informations qui permettent à chaque citoyen de se forger une opinion.
= The journalistic method is not to adopt a moral position, but to investigate the significance and relevance of information and enable every citizen to form an opinion.
Lorsque WikiLeaks lève le voile sur l'analyse par la diplomatie américaine d'enjeux politiques ou autres dans le monde entier, nous considérons en effet que, au regard de la puissance américaine, cela constitue un éclairage important.
= When WikiLeaks reveals the American administration's monitoring of political and other matters somewhere in the world, we consider this to be significant enlightenment with regard to the American government.
Lorsque nous décrivons les systèmes d'interception américains à l'encontre de la diplomatie française aux Etats-Unis, ce n'est en aucun cas pour nous indigner de cette pratique, c'est pour décrire le monde tel qu'il est.
= In describing the American methods of data interception in relation to the French diplomatic representation in the United States, we do not aim at expressing indignation about this practice, but rather at describing the world as it is.
La France a-t-elle bénéficié d'informations fournies par la NSA concernant des opérations terroristes visant nos intérêts ?
= Has France benefited from the intelligence supplied by the NSA concerning terrorist operations against our interests?
Peut-on se priver de la collaboration américaine ?
= Can we do without collaboration with the Americans?
Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler. =
Colon 20-shot
Translate French to English
French: Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
English: Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
French: Selon moi, il y a deux niveaux de réponse de la part du gouvernement français.
English: In my opinion, there are two levels of response from the French government.
French: Lorsque François Hollande téléphone à Barack Obama ou quand le ministre des affaires étrangères Laurent Fabius convoque l'ambassadeur des Etats-Unis, ils réagissent à une vraie découverte, qui est celle de l'ampleur de la surveillance américaine sur l'ensemble des communications en France.
English: When François Hollande telephones Barack Obama, or when Foreign Minister Laurent Fabius summons the Ambassador of the United States, they are responding to a real discovery, that of the scale of America's surveillance of communications within France generally.
French: N'est-il pas surprenant de lire dans les colonnes du Monde à quelques semaines d'intervalle d'une part la reproduction de la correspondance diplomatique américaine et d'autre part une condamnation des écoutes du Quai d'Orsay par la NSA ?
English: And is it not surprising to read in the pages of Le Monde, on the one hand, a reproduction of diplomatic correspondence with the US and, on the other, condemnation of the NSA's spying on the Ministry of Foreign Affairs on the Quai d'Orsay, within a matter of weeks?
French: N'y aurait-il pas comme une vague hypocrisie de votre part ?
English: Is there not an element of hypocrisy on your part?
French: La démarche journalistique n'est pas un positionnement moral, mais la recherche de l'intérêt et de la pertinence d'informations qui permettent à chaque citoyen de se forger une opinion.
English: The journalistic method is not to adopt a moral position, but to investigate the significance and relevance of information and enable every citizen to form an opinion.
French: Lorsque WikiLeaks lève le voile sur l'analyse par la diplomatie américaine d'enjeux politiques ou autres dans le monde entier, nous considérons en effet que, au regard de la puissance américaine, cela constitue un éclairage important.
English: When WikiLeaks reveals the American administration's monitoring of political and other matters somewhere in the world, we consider this to be significant enlightenment with regard to the American government.
French: Lorsque nous décrivons les systèmes d'interception américains à l'encontre de la diplomatie française aux Etats-Unis, ce n'est en aucun cas pour nous indigner de cette pratique, c'est pour décrire le monde tel qu'il est.
English: In describing the American methods of data interception in relation to the French diplomatic representation in the United States, we do not aim at expressing indignation about this practice, but rather at describing the world as it is.
French: La France a-t-elle bénéficié d'informations fournies par la NSA concernant des opérations terroristes visant nos intérêts ?
English: Has France benefited from the intelligence supplied by the NSA concerning terrorist operations against our interests?
French: Peut-on se priver de la collaboration américaine ?
English: Can we do without collaboration with the Americans?
French: La mise en place depuis en gros dix ans d'outils technologiques d'interception très puissants par les Etats-Unis, mais aussi par la France, a officiellement été justifiée par la lutte contre le terrorisme.
English: The setting up of high-performance interception technology over practically the past ten years by the United States - and by France - has been officially justified by the fight against terrorism.
French: D'ailleurs, dans ce domaine, la France et les Etats-Unis notamment ont mis en place des procédures de coopération et d'échanges d'informations quasi quotidiens et qui sont décrits de part et d'autre comme essentiels.
English: Furthermore, in this regard, France and the United States in particular have implemented procedures, sometimes described as essential, for cooperating and exchanging information on an almost daily basis.
French: A titre d'exemple, la présence de Mohammed Merah dans les zones tribales à Miranshah a été signalée aux Français grâce aux moyens de la NSA.
English: For example, France was informed of the presence of Mohammed Merah in the tribal areas of Miranshah through the NSA's resources.
French: La France peut être conduite, par exemple, à transmettre des blocs entiers de données sur la région du Sahel aux services américains, et, en contrepartie - on l'a déjà rapidement dit -, les Américains peuvent donner des informations aux Français sur d'autres régions du monde.
English: Also France may, for example, have to transmit entire blocks of data on the Sahel region to the Americans and, in return - as already briefly mentioned - the Americans may provide information to the French about other parts of the world.
French: Donc la question de fond derrière cette affaire NSA n'est pas tant la capacité ou le droit des pays de se doter d'outils d'interception, que la question de l'absence totale de débat préalable, notamment au sein des Parlements, sur la justification de tels systèmes, le périmètre qui doit être le leur, et, en fin de compte, la question des atteintes aux libertés.
English: Hence the question at the heart of the NSA affair is not so much the capacity or the right of a country to use interception tools, as the issue of the complete lack of prior debate - especially within parliaments - on the justification of such systems, the extent to which they should be used and, ultimately, the issue of the infringement of freedoms.
French: Que risquent réellement les Etats-Unis ? une dégradation de leur image?
English: What risk does the United States actually run? Ruining its image?
French: On a beau les dénoncer, je ne vois pas de quelle manière ils pourront être punis.
English: However much we denounce the US, I see no way in which it can be punished.
French: Le risque couru par les Américains peut être double.
English: The risk run by the Americans could be twofold.
French: Le premier, c'est lorsque leurs alliés - et ça a été le cas récemment - apprennent que leurs dirigeants, parfois au plus haut sommet de leur Etat, ont été surveillés.
English: The first is when their allies - as has been the case recently - learn that their governments have been spied on, sometimes at the highest level.
French: C'est le cas du Brésil et de l'Allemagne, deux pays où les relations diplomatiques avec les Etats-Unis se sont tendues.
English: This is the case in Brazil and Germany, two countries where diplomatic relations with the United States are strained.
French: Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler.
English:
OpenAI 20-shot
Translate French to English
Comment expliquer l'attitude contradictoire du gouvernement français, qui d'un coté s'offusque en public en convoquant l'ambassadeur des Etats-Unis le 21 octobre, et de l'autre interdit le survol du territoire par l'avion présidentiel bolivien, sur la base de la rumeur de la présence à son bord d'Edward Snowden ?
= Why the contradictory attitude of the French government? On the one hand, it publicly takes offence and summons the Ambassador of the United States on October 21 and, on the other, it forbids the Bolivian president's plane to enter its air space on the basis of a rumor that Edward Snowden was on board?
Selon moi, il y a deux niveaux de réponse de la part du gouvernement français.
= In my opinion, there are two levels of response from the French government.
Lorsque François Hollande téléphone à Barack Obama ou quand le ministre des affaires étrangères Laurent Fabius convoque l'ambassadeur des Etats-Unis, ils réagissent à une vraie découverte, qui est celle de l'ampleur de la surveillance américaine sur l'ensemble des communications en France.
= When François Hollande telephones Barack Obama, or when Foreign Minister Laurent Fabius summons the Ambassador of the United States, they are responding to a real discovery, that of the scale of America's surveillance of communications within France generally.
N'est-il pas surprenant de lire dans les colonnes du Monde à quelques semaines d'intervalle d'une part la reproduction de la correspondance diplomatique américaine et d'autre part une condamnation des écoutes du Quai d'Orsay par la NSA ?
= And is it not surprising to read in the pages of Le Monde, on the one hand, a reproduction of diplomatic correspondence with the US and, on the other, condemnation of the NSA's spying on the Ministry of Foreign Affairs on the Quai d'Orsay, within a matter of weeks?
N'y aurait-il pas comme une vague hypocrisie de votre part ?
= Is there not an element of hypocrisy on your part?
La démarche journalistique n'est pas un positionnement moral, mais la recherche de l'intérêt et de la pertinence d'informations qui permettent à chaque citoyen de se forger une opinion.
= The journalistic method is not to adopt a moral position, but to investigate the significance and relevance of information and enable every citizen to form an opinion.
Lorsque WikiLeaks lève le voile sur l'analyse par la diplomatie américaine d'enjeux politiques ou autres dans le monde entier, nous considérons en effet que, au regard de la puissance américaine, cela constitue un éclairage important.
= When WikiLeaks reveals the American administration's monitoring of political and other matters somewhere in the world, we consider this to be significant enlightenment with regard to the American government.
Lorsque nous décrivons les systèmes d'interception américains à l'encontre de la diplomatie française aux Etats-Unis, ce n'est en aucun cas pour nous indigner de cette pratique, c'est pour décrire le monde tel qu'il est.
= In describing the American methods of data interception in relation to the French diplomatic representation in the United States, we do not aim at expressing indignation about this practice, but rather at describing the world as it is.
La France a-t-elle bénéficié d'informations fournies par la NSA concernant des opérations terroristes visant nos intérêts ?
= Has France benefited from the intelligence supplied by the NSA concerning terrorist operations against our interests?
Peut-on se priver de la collaboration américaine ?
= Can we do without collaboration with the Americans?
La mise en place depuis en gros dix ans d'outils technologiques d'interception très puissants par les Etats-Unis, mais aussi par la France, a officiellement été justifiée par la lutte contre le terrorisme.
= The setting up of high-performance interception technology over practically the past ten years by the United States - and by France - has been officially justified by the fight against terrorism.
D'ailleurs, dans ce domaine, la France et les Etats-Unis notamment ont mis en place des procédures de coopération et d'échanges d'informations quasi quotidiens et qui sont décrits de part et d'autre comme essentiels.
= Furthermore, in this regard, France and the United States in particular have implemented procedures, sometimes described as essential, for cooperating and exchanging information on an almost daily basis.
A titre d'exemple, la présence de Mohammed Merah dans les zones tribales à Miranshah a été signalée aux Français grâce aux moyens de la NSA.
= For example, France was informed of the presence of Mohammed Merah in the tribal areas of Miranshah through the NSA's resources.
La France peut être conduite, par exemple, à transmettre des blocs entiers de données sur la région du Sahel aux services américains, et, en contrepartie - on l'a déjà rapidement dit -, les Américains peuvent donner des informations aux Français sur d'autres régions du monde.
= Also France may, for example, have to transmit entire blocks of data on the Sahel region to the Americans and, in return - as already briefly mentioned - the Americans may provide information to the French about other parts of the world.
Donc la question de fond derrière cette affaire NSA n'est pas tant la capacité ou le droit des pays de se doter d'outils d'interception, que la question de l'absence totale de débat préalable, notamment au sein des Parlements, sur la justification de tels systèmes, le périmètre qui doit être le leur, et, en fin de compte, la question des atteintes aux libertés.
= Hence the question at the heart of the NSA affair is not so much the capacity or the right of a country to use interception tools, as the issue of the complete lack of prior debate - especially within parliaments - on the justification of such systems, the extent to which they should be used and, ultimately, the issue of the infringement of freedoms.
Que risquent réellement les Etats-Unis ? une dégradation de leur image?
= What risk does the United States actually run? Ruining its image?
On a beau les dénoncer, je ne vois pas de quelle manière ils pourront être punis.
= However much we denounce the US, I see no way in which it can be punished.
Le risque couru par les Américains peut être double.
= The risk run by the Americans could be twofold.
Le premier, c'est lorsque leurs alliés - et ça a été le cas récemment - apprennent que leurs dirigeants, parfois au plus haut sommet de leur Etat, ont été surveillés.
= The first is when their allies - as has been the case recently - learn that their governments have been spied on, sometimes at the highest level.
C'est le cas du Brésil et de l'Allemagne, deux pays où les relations diplomatiques avec les Etats-Unis se sont tendues.
= This is the case in Brazil and Germany, two countries where diplomatic relations with the United States are strained.
Un homme de Cambridge a revendiqué la responsabilité de cet acte sur son compte Twitter, où il a posté des images d'Adolf Hitler. =
English target
A man from Cambridge claimed responsibility for the act on his Twitter account, where he posted pictures of Adolf Hitler.
Results:
Likelihood correct - Control
| Engine | Empty prior | Control |
|---|---|---|
| ada | -73.354 | -45.109 |
| babbage | -70.899 | -35.969 |
| curie | -70.224 | -30.489 |
| davinci | -67.642 | -22.543 |
Likelihood correct - Simple colon prompt
| Engine | 0-shot | 1-shot | 2-shot | 5-shot | 10-shot | 20-shot |
|---|---|---|---|---|---|---|
| ada | -19.658 | -17.257 | -16.519 | -16.112 | -15.741 | -16.309 |
| babbage | -10.467 | -11.404 | -11.574 | -12.385 | -13.134 | -11.462 |
| curie | -9.395 | -8.763 | -8.561 | -8.865 | -8.701 | -7.701 |
| davinci | -6.443 | -6.658 | -6.614 | -6.807 | -7.388 | -6.387 |
Likelihood correct - OpenAI prompt
| Engine | 0-shot | 1-shot | 2-shot | 5-shot | 10-shot | 20-shot |
|---|---|---|---|---|---|---|
| ada | -27.656 | -17.372 | -16.043 | -15.672 | -16.115 | -15.877 |
| babbage | -11.877 | -12.015 | -12.205 | -12.868 | -13.800 | -11.765 |
| curie | -13.414 | -8.735 | -8.841 | -8.462 | -8.685 | -7.147 |
| davinci | -7.271 | -6.549 | -6.532 | -6.805 | -7.392 | -6.544 |
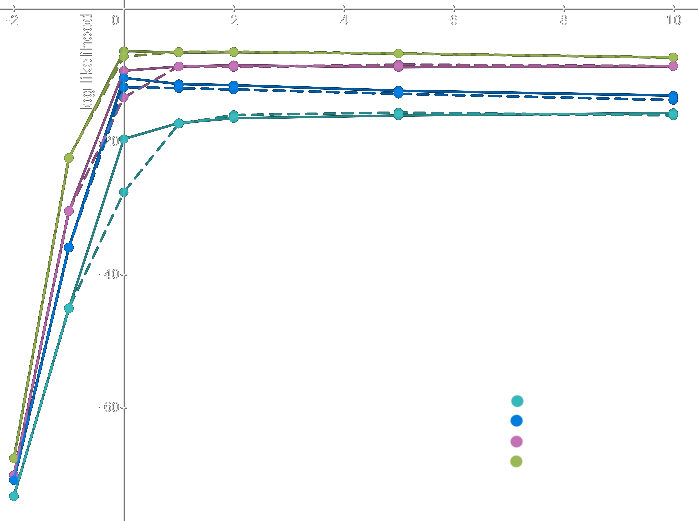 Empty prior is plotted at -2, control prior at -1. Did not plot 20 shot; is was not substantially different from 10-shot for any of the models
Empty prior is plotted at -2, control prior at -1. Did not plot 20 shot; is was not substantially different from 10-shot for any of the models
Observations:
Unlike in the Roish example, for all models, and for both prompts, the change from the control prior to 0-shot is a much bigger change than from 0- to 1-shot.
The OpenAI prompt and simple colon prompt have similar scores for everything except for 0-shot, where the simple colon prompt provides better evidence, especially for
ada.For the simple colon prompt, all the models except
ada, which gleaned some evidence from 1-shot, examples provided no evidence or negative evidence.adaandcuriegleaned more evidence from 1-shot for OpenAI’s prompt due to having derived comparatively less evidence from the 0-shot prompt.For all the models, the transition from the empty prior (no prompt) to control (prompt is French sentence without directions to translate) provided more evidence for the correct answer than any instruction or examples. This makes sense – the most significant evidence for the correct English translation is not actually the instructions to translate, but the French sentence itself.
Now for the decibel breakdown:
ada
| Prompt | Correct likelihood | +dB to empty prior | +dB to control | +dB to 0-shot |
|---|---|---|---|---|
| empty prior | -73.354 | - | - | - |
| control | -45.109 | 28.245 | - | - |
| colon 0-shot | -19.658 | 53.696 | 25.451 | - |
| colon 1-shot | -17.257 | 56.097 | 27.852 | 2.401 |
| colon 2-shot | -16.519 | 56.835 | 28.590 | 3.139 |
| colon 5-shot | -16.112 | 57.243 | 28.998 | 3.547 |
| colon 10-shot | -15.741 | 57.614 | 29.368 | 3.917 |
| colon 20-shot | -16.309 | 57.045 | 28.800 | 3.349 |
| OAI 0-shot | -27.656 | 45.699 | 17.454 | - |
| OAI 1-shot | -17.372 | 55.983 | 27.738 | 10.284 |
| OAI 2-shot | -16.043 | 57.311 | 29.066 | 11.613 |
| OAI 5-shot | -15.672 | 57.682 | 29.437 | 11.983 |
| OAI 10-shot | -16.115 | 57.239 | 28.994 | 11.541 |
| OAI 20-shot | -15.877 | 57.477 | 29.232 | 11.778 |
Simple colon +dB from 20-shot / +dB from 0-shot = 3.349 / 25.451 = 0.132
OpenAI +dB from 20-shot / +dB from 0-shot = 11.778 / 17.454 = 0.675
babbage
| Prompt | Correct likelihood | +dB to empty prior | +dB to control | +dB to 0-shot |
|---|---|---|---|---|
| empty prior | -70.899 | - | - | - |
| control | -35.969 | 34.930 | - | - |
| colon 0-shot | -10.467 | 60.432 | 25.502 | - |
| colon 1-shot | -11.404 | 59.495 | 24.565 | -0.937 |
| colon 2-shot | -11.574 | 59.326 | 24.396 | -1.106 |
| colon 5-shot | -12.385 | 58.514 | 23.584 | -1.918 |
| colon 10-shot | -13.134 | 57.765 | 22.835 | -2.666 |
| colon 20-shot | -11.462 | 59.438 | 24.508 | -0.994 |
| OAI 0-shot | -11.877 | 59.022 | 24.021 | - |
| OAI 1-shot | -12.015 | 58.884 | 23.954 | -0.139 |
| OAI 2-shot | -12.205 | 58.694 | 23.758 | -0.329 |
| OAI 5-shot | -12.847 | 58.052 | 23.122 | -0.971 |
| OAI 10-shot | -13.800 | 57.100 | 22.170 | -1.923 |
| OAI 20-shot | -11.765 | 59.134 | 24.167 | 0.111 |
Simple colon +dB from 20-shot / +dB from 0-shot = -0.994 / 25.502 = -0.039
OpenAI +dB from 20-shot / +dB from 0-shot = 0.111 / 24.021 = 0.005
curie
| Prompt | Correct likelihood | +dB to empty prior | +dB to control | +dB to 0-shot |
|---|---|---|---|---|
| empty prior | -70.224 | - | - | - |
| control | -30.489 | 39.735 | - | - |
| colon 0-shot | -9.395 | 60.829 | 21.094 | - |
| colon 1-shot | -8.763 | 61.461 | 21.726 | 0.632 |
| colon 2-shot | -8.561 | 61.663 | 21.928 | 0.834 |
| colon 5-shot | -8.865 | 61.359 | 21.624 | 0.530 |
| colon 10-shot | -8.701 | 61.523 | 21.743 | 0.694 |
| colon 20-shot | -7.701 | 62.524 | 22.744 | 1.695 |
| OAI 0-shot | -13.414 | 56.810 | 17.075 | - |
| OAI 1-shot | -8.735 | 61.489 | 21.754 | 4.679 |
| OAI 2-shot | -8.841 | 61.383 | 21.648 | 4.573 |
| OAI 5-shot | -8.462 | 61.762 | 22.027 | 4.952 |
| OAI 10-shot | -8.685 | 61.539 | 21.804 | 4.729 |
| OAI 20-shot | -7.147 | 63.077 | 23.342 | 6.267 |
Simple colon +dB from 20-shot / +dB from 0-shot = 1.695 / 21.094 = 0.080
OpenAI +dB from 20-shot / +dB from 0-shot = 6.267 / 17.075 = 0.367
davinci
| Prompt | Correct likelihood | +dB to empty prior | +dB to control | +dB to 0-shot |
|---|---|---|---|---|
| empty prior | -67.642 | - | - | - |
| control | -22.543 | 45.099 | - | - |
| colon 0-shot | -6.443 | 61.199 | 16.100 | - |
| colon 1-shot | -6.658 | 60.984 | 15.884 | -0.215 |
| colon 2-shot | -6.614 | 61.028 | 15.911 | -0.171 |
| colon 5-shot | -6.807 | 60.835 | 15.749 | -0.364 |
| colon 10-shot | -7.388 | 60.254 | 15.167 | -0.945 |
| colon 20-shot | -6.387 | 61.255 | 16.169 | 0.056 |
| OAI 0-shot | -7.286 | 60.368 | 15.269 | - |
| OAI 1-shot | -6.567 | 61.087 | 15.975 | 0.719 |
| OAI 2-shot | -6.506 | 61.148 | 16.093 | 0.779 |
| OAI 5-shot | -6.797 | 60.857 | 15.835 | 0.489 |
| OAI 10-shot | -7.392 | 60.262 | 15.184 | -0.106 |
| OAI 20-shot | -6.528 | 61.126 | 15.966 | 0.757 |
Simple colon +dB from 20-shot / +dB from 0-shot = 0.056 / 16.100 = 0.003
OpenAI +dB from 20-shot / +dB from 0-shot = 0.757 / 15.269 = 0.050
We see again that the more powerful models derive proportionally more evidence from the 0-shot task description than from subsequent examples, although compared to Roish, all the models derive a lot more evidence from the 0-shot description than from examples (the ratio is consistently < 1, whereas for Roish it was consistently > 1). These two tasks, one which uses an invented language and one which uses a real language that GPT-3 knows well, derive evidence from 0- and few-shot prompts in different proportions. When GPT-3 already knows how to perform a task, examples are less helpful.
Using the simple colon prompt, none of the models except for ada appear to have much use for examples in terms of the likelihood of giving the correct translation. OpenAI’s prompt results in worse 0-shot accuracy for ada and curie, and accordingly the presence of one example is helpful for those two models, but any additional examples have little effect.
This supports the hypothesis that GPT-3 is not “learning” translation from the few-shot examples but rather locating the already-learned task, and that the lower BLEU scores for 0-shot prompts can probably be attributed to catastrophic failures.
Counterexample - accuracy decreases with # shots
Main article: List sorting does not play well with few-shot
A interesting counterexample to few-shot monotonicity is list sorting (e.g. [1, 3, 3, 4, 0] -> [0, 1, 3, 3, 4]). A zero-shot prompt which frames the problem as an example embedded in coding documentation achieves 76% accuracy, whereas a 32-shot prompt achieves only 20%. Adding examples to the end of the coding prompt results in a monotonic decrease in accuracy with number of shots.
0-shot code prompt:
The sort function can be used to sort a list in ascending, descending or user defined
order. To sort the list in ascending order, call list.sort(). This will sort a list
of integers so that the smallest integer will be first in the list and the largest
integer will be the last and the last element of the list is the largest."
For example:
list = [1, 0, 4, 3, 3]
list.sort() =
Example-only prompt:
Unsorted list: [5, 6, 2, 3, 2]
Sorted list: [2, 2, 3, 5, 6]
Unsorted list: [8, 5, 8, 8, 4]
Sorted list: [4, 5, 8, 8, 8]
...
Unsorted list: [1, 0, 4, 3, 3]
Sorted list:
Code preprompt, length 5
| Shots | Correct | Accuracy |
|---|---|---|
| 0 | 38/50 | 0.76 |
| 1 | 33/50 | 0.66 |
| 3 | 23/50 | 0.46 |
| 5 | 22/50 | 0.44 |
| 7 | 22/50 | 0.44 |
| 10 | 21/50 | 0.42 |
| 13 | 15/50 | 0.30 |
| 16 | 16/50 | 0.32 |
No preprompt, length 5
| Shots | Correct | Accuracy |
|---|---|---|
| 0 | 14/50 | 0.28 |
| 1 | 20/50 | 0.40 |
| 3 | 15/50 | 0.30 |
| 5 | 14/50 | 0.28 |
| 7 | 16/50 | 0.32 |
| 10 | 25/50 | 0.50 |
| 13 | 18/50 | 0.36 |
| 16 | 11/50 | 0.22 |
| 32 | 10/50 | 0.20 |
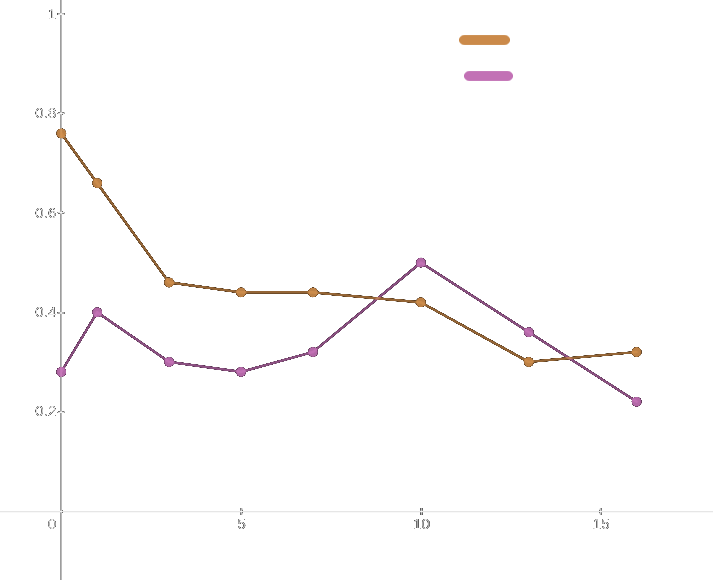 comparison of accuracies from 0 - 16 shots
comparison of accuracies from 0 - 16 shots
Pretty weird, right? I speculate on the causes of these unexpectedly shaped plots in my post about this experiment. Regardless of the mechanism, though, the fact that having more examples in the prompt makes GPT-3 worse at the task implies that there are more factors in play than simply metalearning.
List sorting is the only quantitative task that I know to exhibit strict decrease in accuracy with number of shots, but I suspect there are many more.
Predictions
I will offer some specific predictions suggested by my interpretation of these results, which may be corroborated or falsified by further experiments and future developments.
For translation tasks, if catastrophic failures are filtered out, the discrepancy between 0-shot and 64-shot performance will disappear.
- 1-shot performance, however, will be worse than both 0-shot and 64-shot performance even after catastrophic failures are filtered out, due to being most vulnerable to few-shot bugs.
For practically all tasks that can be meaningfully described using a 0-shot prompt, the ratio of + dB from few-shot over 0-shot / +dB from 0-shot over prior will tend to be smaller for larger models than smaller models, indicating that larger models glean more evidence from 0-shot task descriptions compared to examples.
There are tasks for which a zero-shot prompt causes GPT-3 to perform better than any conventional3 few-shot prompt. Sorting lists of five integers is probably one such task.
More powerful language models released in the future will continue to become more effective at 0-shot “learning,” and this capability will increase even more dramatically than improvement at few-shot learning.
This is probably the situation for many zero-shot translation tasks with inadequate task specification. ↩︎
Of course, the representativeness of examples is always a concern when evaluating language models. ↩︎
Conventional = a list of solved examples, optionally following a task description, excluding complex embeddings of examples e.g. in a narrative. ↩︎